
Quickly approximating Shapley Games

In this blog post, we will talk about some recent advances in algorithms for approximately solving Shapley Games.
What is a Shapley Game?
At an intuitive level, Shapley games capture the idea of extending one-shot 2-player games to be occurring over multiple stages.
Explicitly, Shapley games are played on an underlying state space 




![A_v[i,j]\in \mathbb R](https://s0.wp.com/latex.php?latex=A_v%5Bi%2Cj%5D%5Cin+%5Cmathbb+R&bg=ffffff&fg=000000&s=0&c=20201002)
![-A_v[i,j]](https://s0.wp.com/latex.php?latex=-A_v%5Bi%2Cj%5D&bg=ffffff&fg=000000&s=0&c=20201002)

](https://s0.wp.com/latex.php?latex=P_v%5Bi%2Cj%5D%28u%29&bg=ffffff&fg=000000&s=0&c=20201002)

 = 1 - q](https://s0.wp.com/latex.php?latex=%5Csum_%7Bu%5Cin+V%7D+P_v%5Bi%2Cj%5D%28u%29+%3D+1+-+q&bg=ffffff&fg=000000&s=0&c=20201002)
These games were introduced by [Shapley’53], where he also proved that when 
Furthermore, this value can be characterized as the solution to a specific fixed point equation: defining 







We are often interested in the setting where 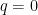
Connecting Shapley Games to Fixed Point Theorems
As we talked about above, the value of a Shapley Game is the unique vector 

- Monotonicity: for every
,
- Contraction: for every
,
- Later, we will also care about defining a contraction property for discrete functions: in this case, we loosen the constraint to be
(else, all values are actually equal)
- Later, we will also care about defining a contraction property for discrete functions: in this case, we loosen the constraint to be


By Tarski’s Fixed Point Theorem, every monotone function has a fixed point; and by Banach’s Fixed Point Theorem, every contracting function also has a fixed point.
For our algorithms, we will not be interested in the exact Shapley value, but just an 


Then, [EPRY’20] constructs a (discrete) monotone contraction ![F: [n]^d \rightarrow [n]^d](https://s0.wp.com/latex.php?latex=F%3A+%5Bn%5D%5Ed+%5Crightarrow+%5Bn%5D%5Ed&bg=ffffff&fg=000000&s=0&c=20201002)
- A query to
requires one query to an oracle for
- Given any
, we can construct in polynomial time an
such that
.
. This last condition is an implementation detail which will make some of the later exposition simpler.
With this reduction in mind, the challenge for approximately solving Shapley Games has just become one of finding monotone/contracting/both fixed points of a function over ![[n]^d](https://s0.wp.com/latex.php?latex=%5Bn%5D%5Ed&bg=ffffff&fg=000000&s=0&c=20201002)
It’s important to note which factors are important for the runtime and query and complexity here: we will often consider 


Complexity Implications
Before describing algorithms for approximately solving Shapley Games, let’s take a look at the complexity landscape surrounding it.

Above is a diagram of the relevant complexity classes surrounding Shapley Games. These are, in order:
- PPAD: A prototypical complete problem for PPAD is End-Of-Line: Given an (exponentially large) directed graph consisting of lines and cycles and a start point of a line, find the end of one of the lines. Two famous examples of problems complete for PPAD are finding (approximate) Nash Equilibria and Brouwer Fixed Points (Given a compact domain
and a continuous function
, find an
).
- PLS (Polynomial Local Search): A prototypical complete problem for PLS is the following: given an (exponentially large) DAG and a potential function
- CLS (Continuous Local Search): An example complete problem for CLS is Gradient Descent. It is also known that
(shown in [FGHS’22]).
- UEOPL (Unique End of Potential Line): There is a hidden class not in the above diagram: EOPL (End Of Potential Line). This marries the prototypical complete problems for PPAD and PLS by adding a potential function to End-Of-Line. Building on this, UEOPL asks for there to be exactly one line (and hence exactly one solution). By definition, this lies within
.
From first principles, it is true that computing the (approximate) Shapley values lies both within PPAD and PLS (and hence within CLS), by noticing that it is a special case of Brouwer’s Fixed Point Theorem and admits the potential function 
Algorithms
Inefficient Algorithms
Let’s begin by “forgetting” the contracting constraint and just trying to find a fixed point of a monotone ![F : [n]^d\rightarrow [n]^d](https://s0.wp.com/latex.php?latex=F+%3A+%5Bn%5D%5Ed%5Crightarrow+%5Bn%5D%5Ed&bg=ffffff&fg=000000&s=0&c=20201002)




In the opposite direction, suppose we just knew that 

On the other hand, exciting new work by [CLY’24] gave an algorithm with query complexity 

By contrast, in the upcoming algorithms, we will have the property that the “external” runtime is at most some 
We will now describe some algorithms for computing fixed points of monotone contractions. The current state of the art is an algorithm by [BFGMS’25] that takes 

First Pass: Monotone Fixed Point Algorithms
On the path to faster algorithms, let’s begin with 




Similarly, we can do a recursive 
To improve this algorithm, let’s decompose it into two parts: a base case and a gluing theorem.
- The base case here is solving
- The “gluing theorem” says that if we can find a fixed point of a
, then we can find a fixed point of a
-dimensional
.
One road to improving the runtime of this algorithm is to improve the base case. That is, is there some fixed constant 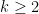


Recent work in [BPR’25] has given a lower bound of 

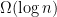
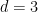
Given a monotone
, there is an algorithm which takes
queries and outputs an
Immediately, this implies an algorithm taking 
If we can find fixed points of
dimensional
respectively, then we can find the fixed point of a
dimensional
.
Together, these imply an algorithm running in time 
Gluing Theorem
Let’s begin by discussing a variant of the gluing theorem from [BFGMS’25]. In particular, suppose that we have oracles 


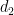
As a first pass, consider giving to 
The issue, however is that 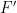
![[n]^{d_2}](https://s0.wp.com/latex.php?latex=%5Bn%5D%5E%7Bd_2%7D&bg=ffffff&fg=000000&s=0&c=20201002)
Proof
We claim that this is sufficient to force 

- If
, then
.
- It is true that
(we prove this when
, which can then be extended by induction)
To prove the first fact, we claim that for every 








Thus, we may consider the sequence 




Now, suppose 



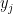
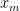
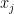


With this in mind, the final question is: how can we find a Least Fixed Point? If 

Base Case of [FPS’22]
We will briefly describe the parts of the base case algorithm from [FPS’22] that we will later use to inform our algorithm for monotone contractions.
To describe the base case algorithm, we need the following definition:
Given a function
and
.
Finding a fixed point is equivalent to finding a point in 
- For a fixed
, find some vector
with
in
- Binary search on
Overall we run the first step
Brief Aside: Gluing Up & Down Points
Before discussing the [BFGMS’25] result, it’s worth mentioning that it is also possible to write a gluing theorem which uses just the first step of the above base case: that is, given oracles which compute either an Up or Down point (given a fixed coordinate), glue them together to find either an Up or Down point of a 
The Power of Monotone Contractions
We are finally ready to bring everything together to describe our
We will apply this idea to re-use work from prior iterations, so that the total amortized cost of the binary searches comes out to 
We will require two properties to hold for our ![F: [n]^2\rightarrow [n]^2](https://s0.wp.com/latex.php?latex=F%3A+%5Bn%5D%5E2%5Crightarrow+%5Bn%5D%5E2&bg=ffffff&fg=000000&s=0&c=20201002)
: recall that we have this for free from the [EPRY’20] reduction.
- If
then there exists no other
with
; and similarly for
-dimensional slice of
- We can achieve this as follows: if
and
, then set
(else, set it to
). We can do the same in the
- We can achieve this as follows: if
Since each 

With this in mind, we can plot these functions:

Here, the blue line corresponds to
Note that both ![\text{Up}(f) \cap \{x = i\} = [a_i, b_i]](https://s0.wp.com/latex.php?latex=%5Ctext%7BUp%7D%28f%29+%5Ccap+%5C%7Bx+%3D+i%5C%7D+%3D+%5Ba_i%2C+b_i%5D&bg=ffffff&fg=000000&s=0&c=20201002)

![\text{Up}(f) \cap \{x = j\} \subseteq [a_i + (j - i), b_i + (j - i)]](https://s0.wp.com/latex.php?latex=%5Ctext%7BUp%7D%28f%29+%5Ccap+%5C%7Bx+%3D+j%5C%7D+%5Csubseteq+%5Ba_i+%2B+%28j+-+i%29%2C+b_i+%2B+%28j+-+i%29%5D&bg=ffffff&fg=000000&s=0&c=20201002)
From this, we can derive our final algorithm: for a given 
![[1, n]](https://s0.wp.com/latex.php?latex=%5B1%2C+n%5D&bg=ffffff&fg=000000&s=0&c=20201002)
Open Problems
There are a wealth of open problems left here, but we’ll mention two.
- What is the true complexity of computing fixed points of monotone, contracting, and monotone contracting functions? This includes both the query complexity and the runtime, as currently we have a large gap between lower and upper bounds.
- Are there other properties of Shapley Games that allow us to get faster approximate algorithms beyond just using monotonicity and contraction?
Acknowledgements: I would like to thank my quals committee: Nima Anari, Aviad Rubinstein, and Tselil Schramm for the useful feedback on my quals talk and some suggestions on this blog post. I would also like to thank Spencer Compton for valuable comments on this blog post.
References
[BFGMS’25] Batziou, E., Fearnley, J., Gordon, S., Mehta, R., & Savani, R. (2025, June). Monotone Contractions. In Proceedings of the 57th Annual ACM Symposium on Theory of Computing (pp. 507-517).
[BPR’25] Brânzei, S., Phillips, R., & Recker, N. (2025). Tarski Lower Bounds from Multi-Dimensional Herringbones. arXiv preprint arXiv:2502.16679.
[CL’22] Chen, X., & Li, Y. (2022, July). Improved upper bounds for finding tarski fixed points. In Proceedings of the 23rd ACM Conference on Economics and Computation (pp. 1108-1118).
[CLY’24] Chen, X., Li, Y., & Yannakakis, M. (2024, June). Computing a Fixed Point of Contraction Maps in Polynomial Queries. In Proceedings of the 56th Annual ACM Symposium on Theory of Computing (pp. 1364-1373).
[EPRY’20] Etessami, K., Papadimitriou, C., Rubinstein, A., & Yannakakis, M. (2020). Tarski’s Theorem, Supermodular Games, and the Complexity of Equilibria. In 11th Innovations in Theoretical Computer Science Conference (ITCS 2020) (pp. 18-1). Schloss Dagstuhl–Leibniz-Zentrum für Informatik.
[FGHS’22] Fearnley, J., Goldberg, P., Hollender, A., & Savani, R. (2022). The complexity of gradient descent: CLS= PPAD∩ PLS. Journal of the ACM, 70(1), 1-74.
[FPS’22] Fearnley, J., Pálvölgyi, D., & Savani, R. (2022). A faster algorithm for finding Tarski fixed points. ACM Transactions on Algorithms (TALG), 18(3), 1-23.
[Shapley’53] Shapley, L. S. (1953). Stochastic games. Proceedings of the national academy of sciences, 39(10), 1095-1100.

Leave a comment