
DNF Minimization, Part II

In the last post, I discussed the complexity of DNF minimization given a dataset. Specifically, given a dataset 

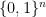
DNF truth table minimization. DNF truth table minimization is the variant of DNF minimization where the input dataset 



It is NP-hard to approximate truth table DNF minimization within a factor of
Feldman 2009.
Allender, Hellerstein, McCabe, Pitassi, and Saks independently obtained the same hardness of approximation under the stronger assumption that 


The proofs of these results use PCP techniques and are significantly more involved than that of DNF minimization in the dataset setting. A key intermediate step is proving hardness for partial truth table minimization. In this variant, the input is still a truth table of size 
Learning hardness. Given access to random labeled samples 


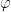


The landscape changes if the learner is allowed to assume that the distribution in the learning instance is uniform. The Pitt-Valiant NP-hardness result crucially relies on constructing a “pathological” distribution which makes the problem hard. In fact, with this new distributional assumption, it is possible to learn size-
There is an algorithm that learns size-
Verbeurgt 1990.
Any algorithm that learns DNFs over the uniform distribution can also be used to solve DNF minimization given a truth table. This observation was made by Feldman. The basic idea is to provide the learner with uniform random samples labeled according to the truth table. Using this observation and the hardness result from Khot and Saket, one can obtain the following learning lower bound which complements the above upper bound.
The following holds for all constants
DNFs in polynomial time. This holds even if the distribution in the learning instance is uniform and the target is a
-junta over
variables.
In fact, the above theorem also holds even if the learner has access to membership queries. This means that in addition to random samples, the learner is allowed to query the function on arbitrary inputs (note Verbeurgt’s algorithm only uses random samples). We also remark that the above theorem requires the learner to output a hypothesis that has accuracy 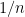

Conclusion and open problems. DNF minimization is a fundamental problem in computer science and has many connections to learning. We’ve seen that assumptions on the structure of the dataset can greatly affect the complexity of the problem, just as distributional assumptions in the learning setting can affect the complexity of the learning task. While a lot of progress has been made on understanding the nuances of these assumptions, there are still many directions to explore:
1. Gaps remain between the approximation lower bounds and the approximation upper bounds for these problems. For example, can one show hardness of approximating DNF minimization in the dataset setting to within a factor of 
2. Can Verbeurgt’s algorithm be improved to run in time 

3. Is it hard to learn DNFs over the uniform distribution to constant error?
That’s it for this blog post! Thanks for reading!

Leave a comment