
Average-Case Fine-Grained Hardness, Part III

Continuing our previous discussion, I will show another application of the new recipe described in the previous post (i.e., constructing a “good” polynomial for a problem of interest), which will establish average-case hardness of a problem related to the orthogonal vector (OV) problem. (Recall the OV problem: Given 





The motivating question is can we show average-case hardness for counting the number of orthogonal pairs in the OV problem by constructing a “good” polynomial? (One motivation is that such average-case hardness result could serve as the source of reductions for proving average-case hardness for many other problems, because OV is a main source of fine-grained hardness.) There is a good reason to believe the answer is no. Specifically, an 

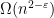

Instead, can we first come up with a nice combinatorial problem that encodes OV on a slightly larger binary input space and then construct a “good” polynomial for counting solutions of this combinatorial problem? (The motivation is that since this combinatorial problems encodes OV, it is at least as hard as OV for worst case, and moreover, if we can construct a “good” polynomial for counting solutions of this combinatorial problem, by the new recipe in the previous post, counting solutions of this combinatorial problem for average case is (almost) as hard as that for worst case. Therefore, counting solutions of this combinatorial problem for average case is at least as hard as OV for worst case. More importantly, this combinatorial problem could serve as the source of reductions thanks to its combinatorial structure.) The factored OV problem introduced in [DLW20] gives a positive answer to this question. Analogously, they proposed factored variants for many other flagship fine-grained hard problems. By reductions to these factored problems, they managed to prove average-case fine-grained hardness for many natural combinatorial problems such as counting regular expression matchings (the featured image of this post is the web of reductions in their paper).
Next, for the purpose of exposition, I briefly sketch the high-level idea behind the factored OV problem (without even explicitly describing its combinatorial interpretation, since I will not show any reduction from this problem).
Counting solutions for factored OV. Given an OV instance 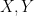


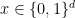
![\textrm{Enc}(x):=\textrm{LONG}(x[1:\sqrt{d}])\circ \textrm{LONG}(x[\sqrt{d}+1:2\sqrt{d}])\circ\dots\circ\textrm{LONG}(x[d-\sqrt{d}+1:d])](https://s0.wp.com/latex.php?latex=%5Ctextrm%7BEnc%7D%28x%29%3A%3D%5Ctextrm%7BLONG%7D%28x%5B1%3A%5Csqrt%7Bd%7D%5D%29%5Ccirc+%5Ctextrm%7BLONG%7D%28x%5B%5Csqrt%7Bd%7D%2B1%3A2%5Csqrt%7Bd%7D%5D%29%5Ccirc%5Cdots%5Ccirc%5Ctextrm%7BLONG%7D%28x%5Bd-%5Csqrt%7Bd%7D%2B1%3Ad%5D%29&bg=ffffff&fg=000000&s=0&c=20201002)
where ![x[i:j]](https://s0.wp.com/latex.php?latex=x%5Bi%3Aj%5D&bg=ffffff&fg=000000&s=0&c=20201002)




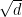
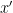



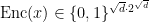


The key advantage of such encoding is that the indicator function ![\mathbf{1}(x[1:\sqrt{d}]\perp y[1:\sqrt{d}])](https://s0.wp.com/latex.php?latex=%5Cmathbf%7B1%7D%28x%5B1%3A%5Csqrt%7Bd%7D%5D%5Cperp+y%5B1%3A%5Csqrt%7Bd%7D%5D%29&bg=ffffff&fg=000000&s=0&c=20201002)



![\textrm{LONG}(x[1:\sqrt{d}])](https://s0.wp.com/latex.php?latex=%5Ctextrm%7BLONG%7D%28x%5B1%3A%5Csqrt%7Bd%7D%5D%29&bg=ffffff&fg=000000&s=0&c=20201002)
![\textrm{LONG}(y[1:\sqrt{d}])](https://s0.wp.com/latex.php?latex=%5Ctextrm%7BLONG%7D%28y%5B1%3A%5Csqrt%7Bd%7D%5D%29&bg=ffffff&fg=000000&s=0&c=20201002)



Using this approach, for each 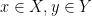
![i\in[\sqrt{d}]](https://s0.wp.com/latex.php?latex=i%5Cin%5B%5Csqrt%7Bd%7D%5D&bg=ffffff&fg=000000&s=0&c=20201002)
![\mathbf{1}(x[(i-1)\sqrt{d}+1:i\sqrt{d}]\perp y[(i-1)\sqrt{d}+1:i\sqrt{d}])](https://s0.wp.com/latex.php?latex=%5Cmathbf%7B1%7D%28x%5B%28i-1%29%5Csqrt%7Bd%7D%2B1%3Ai%5Csqrt%7Bd%7D%5D%5Cperp+y%5B%28i-1%29%5Csqrt%7Bd%7D%2B1%3Ai%5Csqrt%7Bd%7D%5D%29&bg=ffffff&fg=000000&s=0&c=20201002)
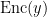
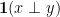




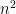
Notice that (i) Since the encoding only blows up the input size mildly, the worst-case hardness of OV (almost) carries over to evaluating this polynomial. (ii) Since 
Finally, I mention two broad research directions in this area: (i) design cryptographic primitives, e.g., one-way functions, based on these fine-grained average-case hardness results (or show complexity barriers) and (ii) prove fine-grained average-case hardness for decision problems (or design more efficient algorithms).
Acknowledgements. I would like to thank my quals committee — Aviad Rubinstein, Tselil Schramm, Li-Yang Tan for valuable feedback to my quals talk.

Leave a comment