
Average-Case Fine-Grained Hardness, Part I

I recently finished my qualifying exam for which I surveyed worst-case to average-case reductions for problems in NP. As part of my survey, I reviewed recent results on average-case hardness in P (a.k.a. average-case fine-grained hardness). I would like to give an overview of some of these results in a series of blog posts, and I want to start by giving some motivations.
Why do we care about average-case fine-grained hardness?
(i) We hope to explain why we are struggling to find faster algorithms for problems in P such as DNA sequencing even for some random large datasets.
(ii) Average-case hard problems in P is useful to cryptography. For example, constructing one-way functions (i.e., functions that are easy to compute but hard to invert) based on worst-case complexity assumptions such as NP 

The most common approach for proving average-case fine-grained hardness is arguably worst-case to average-case reduction, i.e., reducing an arbitrary instance to a number of random instances of which the distribution is polynomial-time sampable. Before I give concrete examples, I want to describe a general recipe for designing such worst-case to average-case reductions. (Some reader might notice that the step 3 of the recipe is same as the argument for proving computing permanent is self-reducible [L91], which essentially uses local decoding for Reed-Muller codes.)
General recipe for worst-case to average-case reductions:
- Choose our favorite hard problem
in P.
- Construct a low-degree (degree-
) polynomial
on
such that
for all
.
- To solve
for worst-case
, compute
for distinct nonzero
using average-case solver (note each
is uniformly random), interpolate univariate polynomial
using these points, and output
which is
- (The above steps already show that evaluating
uniformly random inputs is as hard as solving
for
back to solving
Notice that the above general recipe reduces a worst-case instance to 
Now let us go through a concrete example. Consider one of the flagship problems in fine-grained complexity — orthogonal vector problem (OV): Given 





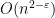


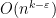
Polynomial evaluation. Given an OV instance 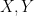
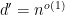

![f_{\textrm{OV}}(X,Y):=\sum_{i,j\in[n]}\prod_{t\in[d']}(1-x_{i,t}y_{i,t})](https://s0.wp.com/latex.php?latex=f_%7B%5Ctextrm%7BOV%7D%7D%28X%2CY%29%3A%3D%5Csum_%7Bi%2Cj%5Cin%5Bn%5D%7D%5Cprod_%7Bt%5Cin%5Bd%27%5D%7D%281-x_%7Bi%2Ct%7Dy_%7Bi%2Ct%7D%29&bg=ffffff&fg=000000&s=0&c=20201002)
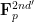





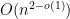
However, the polynomial evaluation problem is algebraic. Next, let us consider a natural combinatorial problem — counting 

Counting 

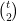
![f_{t\textrm{-clique}}(X):=\sum_{\textrm{size-}t\, T\subseteq [n]}\prod_{i<j\in T} X_{i,j}](https://s0.wp.com/latex.php?latex=f_%7Bt%5Ctextrm%7B-clique%7D%7D%28X%29%3A%3D%5Csum_%7B%5Ctextrm%7Bsize-%7Dt%5C%2C+T%5Csubseteq+%5Bn%5D%7D%5Cprod_%7Bi%3Cj%5Cin+T%7D+X_%7Bi%2Cj%7D&bg=ffffff&fg=000000&s=0&c=20201002)
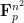


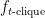
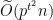

Although this gadget reduction is nice, I will not explain it here, because later works [BBB19, DLW20] show that if the polynomial constructed at the step 2 has certain structure, then there is a general technique to reduce evaluating this polynomial back to the original problem (at the cost of requiring smaller error probability of average-case solver), which I will discuss in the next post. Finally, let me point out an issue in the previous paragraph — 
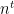


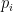
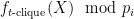
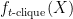
Hopefully, the above examples give you a flavor of worst-case to average-case reductions for fine-grained hard problems. As promised, in the next post, I will continue to discuss the new technique in [BBB19, DLW20], which automatizes the step 4 of the general recipe by requiring more structural properties for the polynomial constructed in the step 2 of the general recipe.
Acknowledgements. I would like to thank my quals committee — Aviad Rubinstein, Tselil Schramm, Li-Yang Tan for valuable feedback to my quals talk.

Looks very interesting, but quite involved. Simple question: Is the average case hardness for k-XOR known? Or are there bounds? I am not an expert, so I am thinking of memory and time complexity, assuming that over space {0,1}^d word operations such as XOR have constant complexity.
LikeLike