In the previous post, we did two examples of proving average-case fine-grained hardness via worst-case to average-case reductions. In this post, I want to continue the discussion of counting  -cliques (in particular, on Erdős–Rényi graphs) to showcase a new technique, which builds on the general recipe and the example of counting -cliques described in the previous post. In the next post, I will discuss how this new technique can be applied to some other combinatorial problems.
-cliques (in particular, on Erdős–Rényi graphs) to showcase a new technique, which builds on the general recipe and the example of counting -cliques described in the previous post. In the next post, I will discuss how this new technique can be applied to some other combinatorial problems.
Counting -cliques in Erdős–Rényi graph. A strong follow-up [BBB19] of the result [GR18] we discussed in the previous post shows that there is an  -time reduction from counting -cliques in any
-time reduction from counting -cliques in any  -vertex graph to counting -cliques with error probability
-vertex graph to counting -cliques with error probability  in Erdős–Rényi graph (whereas the sampable distribution of the random graph in [GR18] is somewhat unnatural). The key idea is a decomposition lemma which says for sufficiently large prime
in Erdős–Rényi graph (whereas the sampable distribution of the random graph in [GR18] is somewhat unnatural). The key idea is a decomposition lemma which says for sufficiently large prime  and
and  , for any constants
, for any constants 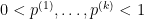 (for our application, these constants will be equal), given independent Bernoulli random variables
(for our application, these constants will be equal), given independent Bernoulli random variables  , the distribution of
, the distribution of  is close to the uniform distribution over
is close to the uniform distribution over  , i.e., the statistical distance is less than
, i.e., the statistical distance is less than  (later when we apply this lemma, we want to be
(later when we apply this lemma, we want to be 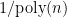 , and therefore
, and therefore  ). We skip the proof of this lemma which is a nice application of basic Fourier analysis.
). We skip the proof of this lemma which is a nice application of basic Fourier analysis.
As in the previous post, 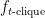 denotes a constructed polynomial that computes the number of -cliques when the input is an adjacency matrix of a graph. The step 3 of the general recipe from the previous post reduces counting -cliques for the worst-case graph to evaluating
denotes a constructed polynomial that computes the number of -cliques when the input is an adjacency matrix of a graph. The step 3 of the general recipe from the previous post reduces counting -cliques for the worst-case graph to evaluating  on
on  many uniformly random
many uniformly random  (recall in the previous post,
(recall in the previous post,  is the degree of the polynomial , and is
is the degree of the polynomial , and is  after the Chinese remaindering trick). Based on the decomposition lemma, using standard sampling scheme (this is essentially rejection sampling, which I will not go into the details, but I just want to mention that we would like the in the decomposition lemma to be such that the sampling scheme succeeds w.h.p. by a few attempts), we can further reduce evaluating on uniformly random to evaluating
after the Chinese remaindering trick). Based on the decomposition lemma, using standard sampling scheme (this is essentially rejection sampling, which I will not go into the details, but I just want to mention that we would like the in the decomposition lemma to be such that the sampling scheme succeeds w.h.p. by a few attempts), we can further reduce evaluating on uniformly random to evaluating  , where each
, where each 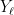 is a random 0-1 valued matrix that is statistically close to the adjacency matrix of an Erdős–Rényi graph. Now, if we can “pull out” the weighted sum in , then we are done, because evaluating on the adjacency matrix of an Erdős–Rényi graph is precisely counting -cliques for Erdős–Rényi graph.
is a random 0-1 valued matrix that is statistically close to the adjacency matrix of an Erdős–Rényi graph. Now, if we can “pull out” the weighted sum in , then we are done, because evaluating on the adjacency matrix of an Erdős–Rényi graph is precisely counting -cliques for Erdős–Rényi graph.
When can we “pull out” the weighted sum for a polynomial  ? One answer is when the polynomial is -partite.
? One answer is when the polynomial is -partite.
An  -variate polynomial
-variate polynomial  is -partite if there is a partition of the set of variables
is -partite if there is a partition of the set of variables ![\dot{\bigcup}_{j\in[d]} S_j=[m]](https://s0.wp.com/latex.php?latex=%5Cdot%7B%5Cbigcup%7D_%7Bj%5Cin%5Bd%5D%7D+S_j%3D%5Bm%5D&bg=ffffff&fg=000000&s=0&c=20201002) such that
such that  is the sum of monomials in which each monomial contains exactly one variable from each part
is the sum of monomials in which each monomial contains exactly one variable from each part  (more formally,
(more formally, ![f(x_1,\dots,x_m)=\sum_{(i_1,i_2,\dots,i_d)\in S}\prod_{j\in[d]}x_{i_j}](https://s0.wp.com/latex.php?latex=f%28x_1%2C%5Cdots%2Cx_m%29%3D%5Csum_%7B%28i_1%2Ci_2%2C%5Cdots%2Ci_d%29%5Cin+S%7D%5Cprod_%7Bj%5Cin%5Bd%5D%7Dx_%7Bi_j%7D&bg=ffffff&fg=000000&s=0&c=20201002) for some
for some  ).
).
For -partite polynomial , it is not hard to show that

(Essentially, because two variables from the same 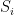 never appear in the same monomial, we can enumerate variables from the same in the same order.)
never appear in the same monomial, we can enumerate variables from the same in the same order.)
Let us think of each 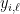 as a coordinate of Erdős–Rényi adjacency matrix , then
as a coordinate of Erdős–Rényi adjacency matrix , then  is evaluating on an ensemble of distinct coordinates of ‘s, and such ensemble is obviously Erdős–Rényi as well. Therefore, we have managed to decompose into sum of
is evaluating on an ensemble of distinct coordinates of ‘s, and such ensemble is obviously Erdős–Rényi as well. Therefore, we have managed to decompose into sum of  many
many  ‘s where each
‘s where each  denotes an Erdős–Rényi adjacency matrix. In the next paragraph, we will construct a
denotes an Erdős–Rényi adjacency matrix. In the next paragraph, we will construct a  -partite polynomial for counting -cliques, and therefore, we have reduced computing to computing
-partite polynomial for counting -cliques, and therefore, we have reduced computing to computing  many
many  ‘s, which is a mild blow-up of the number of the random instances which the reduction needs to solve. (In general, we consider the reduction to be efficient when the number of random instances it needs to solve is
‘s, which is a mild blow-up of the number of the random instances which the reduction needs to solve. (In general, we consider the reduction to be efficient when the number of random instances it needs to solve is  , and hence, as long as
, and hence, as long as  , we are good to go.)
, we are good to go.)
Unfortunately, the given in the previous post does not work. Instead, we first reduce counting -cliques in any graph to counting -cliques in a -partite graph, and then we construct a 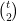 -partite polynomial for counting -cliques in a -partite graph. Reduction from counting -cliques in any graph to counting -cliques in a -partite graph is standard. Simply consider the tensor product between the original graph and another -clique. The number of -cliques in the tensor product graph is exactly
-partite polynomial for counting -cliques in a -partite graph. Reduction from counting -cliques in any graph to counting -cliques in a -partite graph is standard. Simply consider the tensor product between the original graph and another -clique. The number of -cliques in the tensor product graph is exactly  times that in the original graph. Now given the -paritite graph, let
times that in the original graph. Now given the -paritite graph, let 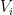 denote the
denote the  -th part of vertices, and let
-th part of vertices, and let 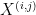 (for
(for  ) denote the adjacency matrix between and
) denote the adjacency matrix between and  . Consider the new polynomial
. Consider the new polynomial ![f_{t\textrm{-clique}}(X^{(1,2)},X^{(1,3)},\dots,X^{(t-1,t)}):=\sum_{v_1\in V_1}\sum_{v_2\in V_2}\dots\sum_{v_t\in V_t}\prod_{(i,j)\in\binom{[t]}{2}} X_{v_i,v_j}^{(i,j)}](https://s0.wp.com/latex.php?latex=f_%7Bt%5Ctextrm%7B-clique%7D%7D%28X%5E%7B%281%2C2%29%7D%2CX%5E%7B%281%2C3%29%7D%2C%5Cdots%2CX%5E%7B%28t-1%2Ct%29%7D%29%3A%3D%5Csum_%7Bv_1%5Cin+V_1%7D%5Csum_%7Bv_2%5Cin+V_2%7D%5Cdots%5Csum_%7Bv_t%5Cin+V_t%7D%5Cprod_%7B%28i%2Cj%29%5Cin%5Cbinom%7B%5Bt%5D%7D%7B2%7D%7D+X_%7Bv_i%2Cv_j%7D%5E%7B%28i%2Cj%29%7D&bg=ffffff&fg=000000&s=0&c=20201002) , where
, where 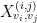 denotes the coordinate that indicates if there is an edge between
denotes the coordinate that indicates if there is an edge between  . Observe that counts -cliques by picking one vertex for each part and checking if these vertices form a clique. It is indeed -partite as each corresponds to a part of variables.
. Observe that counts -cliques by picking one vertex for each part and checking if these vertices form a clique. It is indeed -partite as each corresponds to a part of variables.
New recipe for worst-case to average-case reductions. Let us take a minute to think about what structural properties of counting -cliques we have used in the entire reduction except for constructing .
The answer is none! The only part specific to counting -cliques was cooking up a -partite polynomial for (let us call such polynomial “good”) that encodes this problem. The reduction we showed above works as long as we can construct such “good” polynomial for a problem. Therefore, a new recipe, which was explicitly formulated in [DLW20] for proving average-case (here “average-case” means Erdős–Rényi random input model) fine-grained hardness for a problem  in P, is
in P, is
- Construct a “good” polynomial
 on
on  , where
, where 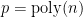 , such that
, such that  for all
for all  .
.
Short and sweet.
In the final post, I will present another instantiation of this new recipe.
Acknowledgements. I would like to thank my quals committee — Aviad Rubinstein, Tselil Schramm, Li-Yang Tan for valuable feedback to my quals talk.



Leave a comment