By Moses Charikar, Ofir Geri, Michael P. Kim, and William Kuszmaul.
The edit distance between two strings  and
and  is the minimum number of insertion, deletion, or substitution operations required to transform into . For example, the edit distance between “track” and “trek” is 2 (remove ‘a’ or ‘c’ and perform one substitution). One of the most important applications of edit distance is in computational biology, as a tool to determine how similar two genetic sequences are.
is the minimum number of insertion, deletion, or substitution operations required to transform into . For example, the edit distance between “track” and “trek” is 2 (remove ‘a’ or ‘c’ and perform one substitution). One of the most important applications of edit distance is in computational biology, as a tool to determine how similar two genetic sequences are.
Computing edit distance is a textbook application of dynamic programming and can be performed in time  for strings of length
for strings of length  . The dynamic programming algorithm can be modified to output not just the edit distance itself, but also a corresponding sequence of edits. The quadratic runtime of the algorithm is prohibitively large for massive datasets (e.g., genomic data), and recent conditional lower bounds (by Backurs and Indyk and by Abboud, Hansen, Vassilevska Williams, and Williams) suggest that no algorithm with run time
. The dynamic programming algorithm can be modified to output not just the edit distance itself, but also a corresponding sequence of edits. The quadratic runtime of the algorithm is prohibitively large for massive datasets (e.g., genomic data), and recent conditional lower bounds (by Backurs and Indyk and by Abboud, Hansen, Vassilevska Williams, and Williams) suggest that no algorithm with run time 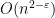 exists.
exists.
The challenge of efficiently computing edit distance has motivated the development of approximation algorithms which run in close to linear time. The state-of-the-art approximation algorithm, due to Andoni, Krauthgamer, and Onak, estimates edit distance within a factor of  and runs in time
and runs in time 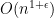 . While these algorithms produce estimates of the edit distance, the equally important question of actually producing an alignment (i.e., the sequence of edits) has received far less attention. To the best of our knowledge, the current best approximation algorithm for producing an alignment has a polynomial multiplicative error.
. While these algorithms produce estimates of the edit distance, the equally important question of actually producing an alignment (i.e., the sequence of edits) has received far less attention. To the best of our knowledge, the current best approximation algorithm for producing an alignment has a polynomial multiplicative error.
The gap between algorithms for estimating edit distance and producing an alignment raises a natural question: Can the current estimation algorithms be used to produce an alignment, or are different techniques needed? In our recent work, we show that any estimation algorithm can be used in a black-box fashion to recover an alignment with modest loss in run time and approximation ratio. Informally, our result takes an estimation algorithm with approximation ratio 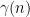 that runs in time
that runs in time 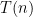 , and produces an algorithm which recovers a
, and produces an algorithm which recovers a  -approximate alignment in time
-approximate alignment in time  . Plugging in the result of Andoni, Krauthgamer, and Onak, we can recover a
. Plugging in the result of Andoni, Krauthgamer, and Onak, we can recover a  -approximate alignment in time .
-approximate alignment in time .
A high-level description of the algorithm is as follows. Let 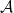 be an algorithm for edit distance estimation. Given strings and , we break into
be an algorithm for edit distance estimation. Given strings and , we break into  equal parts (for some ). We then examine at a low granularity the options for splitting into parts. Using , we approximate the distance between the
equal parts (for some ). We then examine at a low granularity the options for splitting into parts. Using , we approximate the distance between the  -th part of and each of the options for the -th part of . Then, we use dynamic programming to find a partition of into parts which approximately minimizes the sum of the edit distances between parts of and . Finally, we recurse on each of the individual parts. The main ingredient in the analysis is showing that if we consider only a small number of options for each part in ‘s partition, we can still guarantee the existence of a partition which closely approximates the original edit distance between and .
-th part of and each of the options for the -th part of . Then, we use dynamic programming to find a partition of into parts which approximately minimizes the sum of the edit distances between parts of and . Finally, we recurse on each of the individual parts. The main ingredient in the analysis is showing that if we consider only a small number of options for each part in ‘s partition, we can still guarantee the existence of a partition which closely approximates the original edit distance between and .



Leave a comment