
Prediction with a short memory

‘’If any one faculty of our nature may be called more wonderful than the rest, I do think it is memory’’ — Jane Austen
In this blog, we’ll consider the sequential prediction problem of predicting the next observation 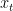

Consider a simple scenario, where the sequence of observations is just a sequence of n bits that keeps repeating (see Fig. 1), and this 
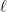
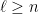
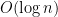
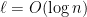


Fig. 1: A simple sequential model of
Is there any hope of making good predictions when 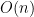
Such questions about the importance of memory and how humans form memories have interested thinkers since back in the time of Plato. Our featured picture is from Christopher Nolan’s Memento, the protagonist here suffers from short-term memory loss approximately every five minutes, and the plot masterfully explores how our memories in some sense shape our reality. There has been considerable interest in the neurosciences community to understand how humans and animals create and retrieve memories to make accurate predictions about their environment (for example, see [1] and [2]). Closer to home, one can ask the question of how algorithms can consolidate and reference memories about the past in order to effectively predict the future.
This question of how to use memory (both how to figure out what to remember, and how to usefully query those memories) has been one of the most significant challenges that practical ML and NLP researchers have been grappling with recently. These efforts have led to a variety of neural network architectures that have an explicit notion of memory, including recurrent neural networks (RNNs), neural Turing machines, memory networks and Long Short-Term Memory (LSTM) networks (for a very nice introduction to these, see this). These advances have obtained some degree of practical success, but seem largely unable to consistently learn long-range dependencies, which are crucial in many settings including language. One amusing example of this is the recent sci-fi short film Sunspring whose script was automatically generated by a LSTM network. Locally, each sentence of the dialogue (mostly) makes sense, though there is no cohesion over longer time frames, and no overarching plot trajectory (despite the brilliant acting). It is an interesting watch — check it out below!
Many fundamental questions in this setting seem ripe for theoretical investigation. i) How much memory is necessary to accurately predict future observations, and what properties of the underlying sequence determine this requirement? ii) Must one remember significant information about the distant past or is a short-term memory sufficient? iii) What is the computational complexity of accurate prediction? iv) How do answers to the above questions depend on the metric that is used to evaluate prediction accuracy? We believe that answers to these questions could both guide the development of practical prediction systems, and help understand how prediction/learning takes place in nature.
In our recent work, we attempt to make progress on the first three questions. Perhaps surprisingly, we show that for a broad class of sequences, the “naive” algorithm that bases its predictions only on the most recent few observation together with a set of simple summary statistics of the past observations, predicts nearly as well as possible on average. The average error here is the error at every time step averaged across time, for a sufficiently large time window (average error is the most natural error metric, and is the metric ubiquitously used in practice). One concrete special case of our more general result concerns sequences generated according to a Hidden Markov Model (HMM) with at most 
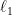



This naive prediction algorithm is simply the 
Interestingly, this result shows that accurate prediction is possible even if the algorithm does not explicitly capture any long-range dependencies. Note that a 
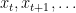

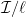


The idea behind these results is most intuitive in the setting of a sequence generated according to an HMM with at most 
These observations shed light on the striking power of the simple Markov model—it can obtain good predictions on average on any data-generating distribution given that its order scales with the mutual information of the sequence. These Markov models, with proper smoothing (i.e. “Kneyser-Ney Smoothing”), were essentially state of the art for natural language generation until till a few years back, and the result perhaps explains some of this success. It also strongly suggests that the widely used metric of average error may not be the right metric to train our algorithms if we want them to learn long-term dependencies, as the trivial Markov model can do pretty well on this metric—even though it is hampered by short-time memory loss (not unlike Memento’s protagonist!). More speculatively, some recent studies have claimed that many animals have very poor short term-memory, could it be that nature also opts for the Markov model when starved for resources?
As mentioned above, the data required to estimate a 


This is a fascinating exploration into memory’s role in prediction.
LikeLike