
When is a dataset robust to outliers?

What properties of a dataset ensure that its mean can be recovered even in the presence of outliers? We answer this question in a recent ITCS paper “Resilience: A Criterion for Learning in the Presence of Arbitrary Outliers” by myself, Moses Charikar, and Greg Valiant. The purpose of this blog post is to give a brief overview of the paper.
For the sake of exposition, I am going to skip over many of the details (as well as many of the results) in order to hopefully convey some of the interesting flavor to someone who is not already thinking about robust estimation.
To start, let us imagine an adversarial game between Alice (the attacker) and Bob (the learner). There is initially a “clean” dataset 
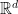


We will consider two types of adversaries:
- Deletion adversaries: If the clean set
elements, Alice is allowed to remove up to
of the elements from
- Addition adversaries: If the clean set
Below is a depiction of a possible strategy when Alice is an addition adversary:
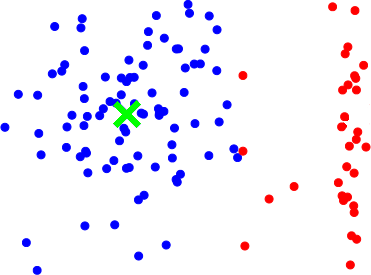
The blue points are the clean data, and Bob wants to estimate the true mean (the green X). Alice has added outliers (in red) to try to fool Bob.
Additions vs. deletions. Intuitively, it seems like addition adversaries should be much more powerful than deletion adversaries—they can add arbitrary additional points to
Note on high dimensions. The naive strategy for handling outliers is to throw away all points that are far away in norm from the empirical mean. However, for say the 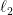


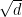
Resilient Sets, and a Pigeonhole Argument
To formalize what we mean by robustness to deletions, we make the following definition:
Definition (Resilience). A set 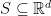
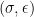
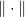



In other words, a set is resilient if every large set (of at least a 

I claimed earlier that robustness to deletions implies robustness to additions. This is formalized in the following proposition:
Proposition (Resilience 
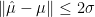

Proof. The proof is a simple pigeonhole argument. Suppose that 


Now let 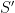


Indeed, by pigeonhole we must have 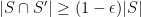


In other words, the mean of 


In summary, it suffices to find any large
Applications
Resilience gives us a way of showing that certain robust estimation problems are possible. For instance, suppose that we have data points 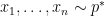
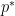




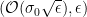
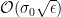

More generally, if a distribution has bounded 

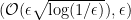
Using other norms (such as the 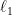
- The
- A truncated
The latter result on stochastic block models requires establishing the surprising fact that robust estimation is possible even with a majority of outliers. I will not go into detail here, but it is possible to show this using a modification of the pigeonhole argument above.
History and Discussion
The problem of outlier-robust learning is very classical, going back at least to Tukey (1970). However, our interest here is in the high-dimensional setting, which surprisingly does not seem to have had satisfactory answers until quite recently. I believe part of this may be due to some historical accident of definitions—in the statistics literature following Tukey, many researchers were interested in developing estimators with good breakdown points. The breakdown point is defined as the maximum fraction of outliers tolerated before the estimator becomes meaningless (for instance, the median has a breakdown point of 50%, while the mean has a breakdown point of 0% because a single outlier can change it arbitrarily). While many estimators have very bad breakdown points, Donoho (1982) and Donoho & Gasko (1992) developed an estimator that had a very good breakdown point of essentially 50% (even in high dimensions). However, the error in the estimator could be as large as
It is only very recently that (computationally-efficient) estimators with small error in high dimensions were developed. Concurrent papers by Lai, Rao, & Vempala (2016) and Diakonikolas, Kamath, Kane, Li, Moitra, & Stewart (2016) showed how to robustly estimate the mean of various distributions in the presence of outliers, with error depending at most logarithmically on the dimension (DKKLMS16 get error completely independent of the dimension). My own interest in this problem came from considering robustness of crowdsourced data collection when some fraction of the raters are dishonest (SVC, 2016). I worked on this problem with Greg and Moses and we later realized that our techniques were actually fairly general and could be used for robustly solving arbitrary convex minimization problems (CSV, 2017).
However, most of this recent work uses fairly sophisticated algorithms and in general I suspect it is not easy for outsiders to this area to understand all of the intuition behind what is going on. This is what motivated considering the information-theoretic question in the previous section, because I think that once we are okay ignoring computational efficiency the picture becomes much clearer.
Other Cool Stuff in the Paper
While I would be happy if the only thing you take away from this blog post is the proof that resilience implies robustness, if you are interested there is some other cool stuff in our paper. Specifically:
- We obtain computationally efficient algorithms in certain settings (including
-norms for
).
- We show that the idea of resilience is applicable beyond mean estimation (in particular, for low-rank recovery).
- We show that for strongly convex norms, the properties of resilience and bounded covariance are closely linked.
To elaborate a bit more on the last point, it is not hard to show that any set whose empirical distribution has bounded covariance is also 
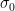
Anyways, hopefully this provides some encouragement to read the full paper, and we would be very interested in any questions or feedback (feel free to leave them in the comments).
References
[CSV17] M. Charikar, J. Steinhardt, and G. Valiant, Learning from untrusted data, Symposium on Theory of Computing (STOC), 2017.
[DKKLMS16] I. Diakonikolas, G. Kamath, D. Kane, J. Li, A. Moitra, and A. Stewart. Robust estimators in high dimensions without the computational intractability. In Foundations of Computer Science (FOCS), 2016.
[D82] D. L. Donoho. Breakdown properties of multivariate location estimators. Ph.D. qualifying paper, 1982.
[DG92] D. L. Donoho and M. Gasko. Breakdown properties of location estimates based on halfspace depth and projected outlyingness. Annals of Statistics, 20(4):1803–1827, 1992.
[LRV16] K. A. Lai, A. B. Rao, and S. Vempala. Agnostic estimation of mean and covariance. In Foundations of Computer Science (FOCS), 2016.
[SCV18] J. Steinhardt, M. Charikar, and G. Valiant, Resilience: A criterion for learning in the presence of arbitrary outliers, Innovations in Theoretical Computer Science (ITCS), 2018.
[SVC16] J. Steinhardt, G. Valiant, and M. Charikar, Avoiding imposters and delinquents: Adversarial crowd-sourcing and peer prediction, Advances in Neural Information Processing Systems (NIPS), 2016.
[T60] J. W. Tukey. A survey of sampling from contaminated distributions. Contributions to probability and statistics, 2:448–485, 1960.
[T75] J. W. Tukey. Mathematics and picturing of data. In ICM, volume 6, pages 523–531, 1975.

Thanks for this nice overview. I spotted a typo: Donaho should be Donoho.
LikeLike
Thanks! Fixed.
LikeLike