The coming Friday we will have the third TOCA-SV meeting in a bit more than a year (here are the details for the first and second meetings). These meetings bring together theoreticians from universities and industry around the Silicon Valley. We welcome and encourage everybody to attend, and have a great program for you.
The event will take place in the Mackenzie Room at the Jen-Hsun Huang Engineering Center (quite close to the CS department). More details, including parking can be found here.
Program:
10:00-10:30 Gathering and coffee
10:30-11:15 Lada Adamic, Facebook
11:30-12 Clément Canonne, Stanford
12 – 12:30 Rad Niazadeh, Stanford
12:30-1:30pm lunch
1:30-2 Thomas Steinke, IBM Almaden
2-3 Students’ short talks
3-3:30 break
3:30-4:00 Rina Panigrahy, Google
4:00-5:30 happy hour
Lada Adamic How cascades grow
Clément Canonne Testing Conditional Independence of Discrete Distributions
We study the problem of testing conditional independence for discrete distributions. Specifically, given samples from a discrete random variable

on domain
![[\ell_1]\times[\ell_2] \times [n]](https://s0.wp.com/latex.php?latex=%5B%5Cell_1%5D%5Ctimes%5B%5Cell_2%5D+%5Ctimes+%5Bn%5D&bg=ffffff&fg=000000&s=0&c=20201002)
,
we want to distinguish, with probability at least
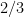
, between the case that

and

are conditionally independent given

from the case that
is

-far, in
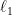
-distance, from every distribution that has this property. Conditional independence is a concept of central importance in probability and statistics with a range of applications in various scientific domains. As such, the statistical task of testing conditional independence has been extensively studied in various forms within the statistics and econometrics communities for nearly a century. Perhaps surprisingly, this problem has not been previously considered in the framework of distribution property testing and in particular no tester with sublinear sample complexity is known, even for the important special case that the domains of
and
are binary.
The main algorithmic result of this work is the first conditional independence tester with \emph{sublinear} sample complexity for
discrete distributions over .
To complement our upper bounds, we prove information-theoretic lower bounds establishing that the sample complexity of our algorithm is optimal, up to constant factors, for a number of settings (and in particular for the prototypical setting when  ).
).
Joint work with Ilias Diakonikolas (USC), Daniel Kane (UCSD), and Alistair Stewart (USC).
Rad Niazadeh Online auctions and multi-scale learning
In this talk, I study revenue maximization in online auctions and pricing. A seller sells an identical item in each period to a new buyer, or a new set of buyers. For the online posted pricing problem, we show regret bounds that scale with the best fixed price, rather than the range of the values. We also show regret bounds that are almost scale free, when comparing to a benchmark that requires a lower bound on the market share. Moreover, we demonstrate a connection between the optimal regret bounds for this online problem and offline sample complexity lower-bounds of approximating optimal revenue, and we show our regret bounds are almost tight with respect to these information theoretic lower-bounds. Our online auctions and pricing are obtained by generalizing the classical learning from experts and multi-armed bandit problems to their “multi-scale versions”, where the reward of each action is in a different range. Here the objective is to design online learning algorithms whose regret with respect to a given action scales with its own range, rather than the maximum range.
Thomas Steinke Less is more: Limiting information to guarantee generalization in adaptive data analysis
Rina Panigrahy Convergence Results for Neural Networks via Electrodynamics
We study whether a depth two neural network can learn another depth two network using gradient descent. Assuming a linear output node, we show that the question of whether gradient descent converges to the target function is equivalent to the following question in electrodynamics: Given k fixed protons in R^d, and k electrons, each moving due to the attractive force from the protons and repulsive force from the remaining electrons, whether at equilibrium all the electrons will be matched up with the protons, up to a permutation. Under the standard electrical force, this follows from the classic Earnshaw’s theorem. In our setting, the force is determined by the activation function and the input distribution. Building on this equivalence, we prove the existence of an activation function such that gradient descent learns at least one of the hidden nodes in the target network. Iterating, we show that gradient descent can be used to learn the entire network one node at a time.
Joint work with Ali Rahimi, Sushant Sachdeva, Qiuyi Zhang



Leave a comment