
Preprocessing attacks on the discrete-log problem
 A NSA-run data center would be one place to store the gigantic "advice string" used in a cryptographic preprocessing attack.
A NSA-run data center would be one place to store the gigantic "advice string" used in a cryptographic preprocessing attack.
A riddle
An old riddle asks: “What is something you never want, but once you have, you never want to lose?” The standard answer is “a bald head.” For a cryptographer, however, an equally good answer is “a hard problem.”
To explain: it would be terrific if all computational problems were easy. However, once we find a candidate hard problem—such as integer factorization—and we start building cryptosystems on top of it, we want that problem to “stay hard” for a long time. So a hard problem is something that we never really want to have, but once we have, we certainly never want to lose.
This post is about the discrete-log problem, which is one hard problem that we certainly don’t want to lose. In this post, we discuss preprocessing attacks on the discrete-log problem, explain their power and limits, and we mention a few new results along the way.
The discrete-log problem
The discrete-log problem is arguably the foundational problem in modern cryptography. It is the problem on which we build the key-exchange protocols, the digital-signature schemes, and the public-key encryption systems that secure our network communications and our e-commerce transactions.
Formally, we define the discrete-log problem relative to a finite cyclic group 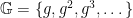


Given: 

Find:

Since a discrete-log instance takes 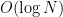
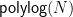
The hardness of the discrete-log problem depends crucially on the choice of the group 
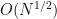
How hard is it really?
One difference between bald heads and hard problems is that it’s not too hard to determine when you have a bald head (I can tell you from personal experience…) but it’s not so easy to know when you have a hard problem. In particular, why should we believe that the discrete-log problem is truly hard in any of the aforementioned groups? Is it possible that there is a much better discrete-log algorithm than these lurking just around the corner? Could some enterprising grad student find a polynomial-time algorithm that solves the discrete-log problem in every group?
In 1997, Shoup showed that the answer to the last question, at least, is a resounding “no:” the best discrete-log algorithm that works in every group must run in strictly exponential time 
Shoup proved this statement formally by defining a notion of “generic” discrete-log algorithms: these are algorithms that are agnostic to the structure of the group
A number of generic discrete-log algorithms, including Shanks’ “Baby Step Giant Step” algorithm and Pollard’s “Rho” algorithm, run in time
Shoup’s lower bound on generic discrete-log is especially interesting because the best algorithms for hard instances of the elliptic-curve discrete-log problem (ECDLP) are the generic ones. Thus, improving on the known ECDLP algorithms will require coming up with new non-generic discrete-log algorithms.
When using elliptic-curve cryptosystems in practice, implementers typically choose 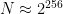
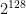
The discrete log monoculture
One funny feature of the Internet’s cryptographic ecosystem is that there are only a handful of groups
However, having everyone on the Internet use one of a small set of standard groups entails some risks. In particular, if an adversary knows which group
In a discrete-log preprocessing attack, an attacker does a huge amount of 

A pair of recent independent results—one due to Mihalcik in 2010 and one due to Bernstein and Lange in 2013—show that even 
Recall that, in a group of order
- operates in every finite cyclic group
- uses
bits of
- runs in online time
much less than
There are two reasons why this
- If
. (The constant inside the big-
is modest.)
- More important, the preprocessing phase of the attack runs in time
, which is more than
for a 256-bit group. This is far far far beyond the reach of even the most sinister government with the most powerful computers and the most clever programmers.
Still, we might worry: Could better preprocessing attacks of this kind exist?
A worrisome feature of such preprocessing attacks is that they evade Shoup’s lower bound: if the preprocessing algorithm runs in time
The prospect of discrete-log preprocessing attacks raises the question: are we in danger of losing one of our favorite hard problems to preprocessing attacks?
The limits of preprocessing attacks
It turns out that, at least as far as generic preprocessing attacks are concerned, things don’t get much worse than the 

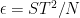
In terms of practicality, the limiting factor of the Mihalcik/Bernstein-Lange attack is almost certainly its prohibitively large 




Distinguishing attacks
An algorithm capable of computing discrete logs would certainly be devastating for many modern cryptosystems. But as is often the case in cryptography, even weaker algorithms—that reveal only partial information about the discrete log (e.g., its last bit)—could compromise the security of such systems. To obtain security guarantees for cryptographic constructions built on top of the discrete-log problem, we often need stronger assumptions than simply the hardness of computing discrete-logs. One of the most common such assumptions is the Decisional Diffie–Hellman assumption. Informally, the DDH problem in a group
A random tuple: 

A “DDH” tuple: 
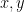
The DDH assumption in a group
However, as we’ve seen in the previous section, attacks with preprocessing don’t always follow the same rules as online-only attacks. We would therefore like to establish the hardness of the DDH problem against this class of attacks as well.
In our paper, we give a lower bound for the DDH problem against attacks with preprocessing. Specifically, we show that any algorithm that uses an advice string of length 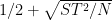

Our lower bound for DDH is not as strong as our lower bound for discrete log: the former bounds the advantage over a random guess by 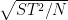

Although this gap remains an open question, we give some evidence in our work that might indicate that the two problems actually differ in their hardness when facing algorithms with preprocessing. Specifically, we show a distinguishing attack with preprocessing on a variant of the DDH problem that achieves advantage 


The distinguishing attack combines two ideas: one is a generic distinguishing attack on any pseudo-random generator described in the Bernstein-Lange paper (which in its turn builds on an earlier work by De, Trevisan, and Tulsiani), and the other is the idea of taking a walk on the elements of the group, and applying the distinguisher only to the set of points that lie at the end of long walks. The combined attack achieves the improved distinguishing advantage.
Open problems
What is left to do here? We leave you with a few open problems that are still nagging at us:
- DDH. In the setting of generic attacks with preprocessing, are DDH and discrete log equally hard? Or is there a better attack on DDH?
- Quantum preprocessing. Say that an attacker may use a quantum computer during the preprocessing phase, but must use a classical computer during the online phase. Does having a quantum computer reduce the preprocessing time at all? For example, is there an algorithm with quantum preprocessing time
- Non-generic attacks. Much of the interest in generic discrete-log algorithms stems from the fact that we don’t have any good non-generic algorithms for popular elliptic-curve groups. Does preprocessing change this state of affairs? Namely, are there non-generic preprocessing attacks on popular elliptic-curve groups (such as Curve25519 or NIST P-256) that outperform their generic counterparts?
Conclusion
We hope this post has been helpful in understanding the importance of considering attacks with preprocessing when thinking about cryptographic problems, and specifically when dealing with discrete-log-like problems. If you want to get more details, please take a look at our full paper or check out our upcoming talk at Eurocrypt 2018.

Would the Mihalcik-Bernstein-Lange results be analogs of Hellman’s original TMTO for DL? I seem to recall Hellman’s precomputation was also O(N^(2/3)) but perhaps my memory fails me.
LikeLike
The Mihalcik and Bernstein-Lange attacks definitely have the same flavor as Hellman’s TMTO attack for inverting one-way functions. As you say, Hellman’s attack gives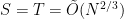 , while the discrete-log attacks are
, while the discrete-log attacks are 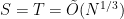 . The generic discrete-log attacks essentially work by finding collisions in random functions, which is easier than inverting random functions. This gives some explanation for the difference in cost between the two attacks.
. The generic discrete-log attacks essentially work by finding collisions in random functions, which is easier than inverting random functions. This gives some explanation for the difference in cost between the two attacks.
LikeLike