
Private and Secure Distributed Matrix Multiplication

Machine learning on big data sets takes a significant amount of computational power, so it is often necessary to offload some of the work to external distributed systems, such as an Amazon EC2 cluster. It is useful to be able to utilize external resources for computation tasks while keeping the actual data private and secure. In particular, matrix multiplication is an essential step in many machine learning processes, but the owner of the matrices may have reasons to keep the actual values protected.
In this post, we’ll discuss four works about secure distributed computation. First, we’ll talk about a method of using MDS (maximum distance separable) error correcting codes to add security and privacy to general data storage (“Cross Subspace Alignment and the Asymptotic Capacity of X-Secure T-Private Information Retrieval” by Jia, Sun, Jafar).
Then we’ll discuss method of adapting a coding strategy for straggler mitigation (“Polynomial codes: an optimal design for high-dimensional coded matrix multiplication” by Yu, Qian, Maddah-Ali, Avestimehr) in matrix multiplication to instead add security or privacy (“On the capacity of secure distributed matrix multiplication” by Chang, Tandon and “Private Coded Matrix Multiplication” by Kim, Yang, Lee)
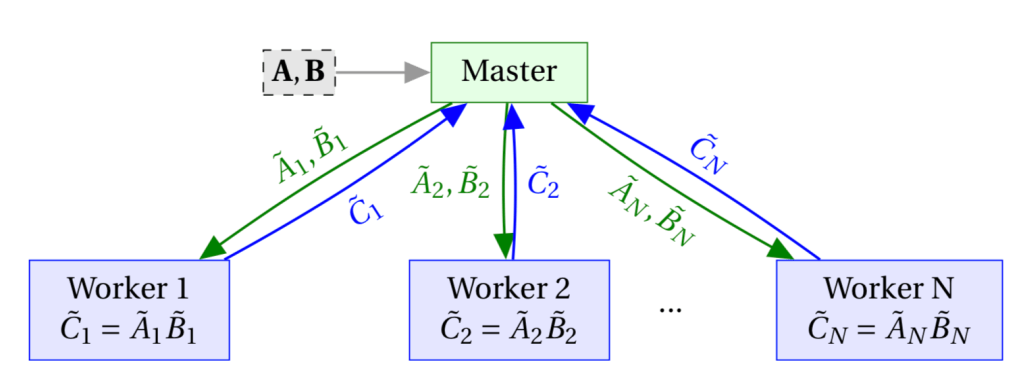
Throughout this post we will use variations on the following communication model:
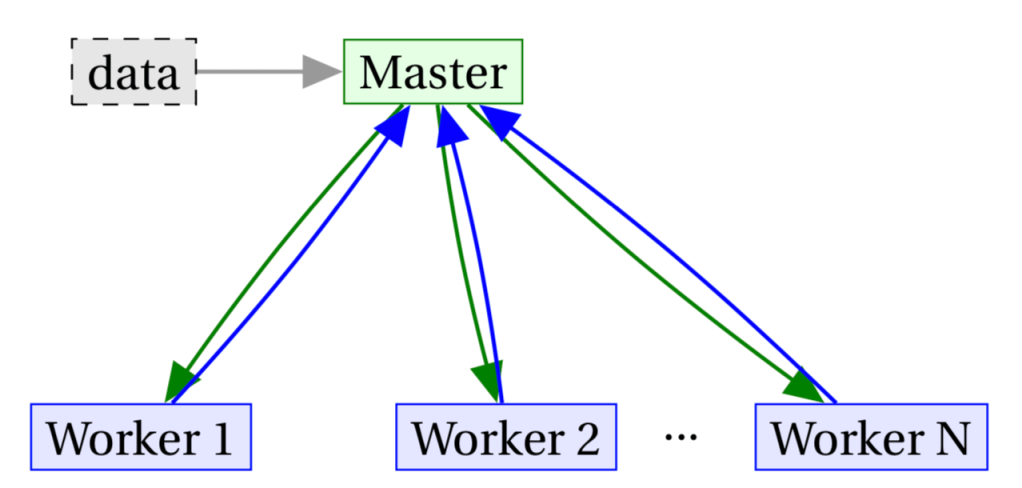
The data in the grey box is only given to the master, so workers only have access to what they receive (via green arrows). Later on we will also suppose the workers have a shared library not available to the master. The workers do not communicate with each other as part of the computation, but we want to prevent them from figuring out anything about the data if they do talk to each other.
This model is related to private computation but not exactly the same. We assume the servers are “honest but curious”, meaning they won’t introduce malicious computations. We also only require the master to receive the final result, and don’t need to protect any data from the master. This is close to the BGW scheme ([Ben-Or, Goldwasser, Wigderson ’88]), but we do not allow workers to communicate with each other as part of the computation of the result.
We consider unconditional or information-theoretic security, meaning the data is protected even if the workers have unbounded computational power. Furthermore, we will consider having perfect secrecy, in which the mutual information between the information revealed to the workers and the actual messages is zero.
X-Secure T-Private Information Retrieval
Before we get into matrix-matrix multiplication, consider the problem of storing information on the workers to be retrieved by the master, such that it is “protected.” What do we mean by that? [Jia, Sun, and Jafar ’19] define X-secure T-private information retrieval as follows:
Let
be a data set of messages, such that each
consists of
random bits. A storage scheme of
on
nodes is
1. X-secure if any set of up to
servers cannot determine anything about any
2. T-private if given a query from the user to retrieve some data element
[Jia, Sun, and Jafar ’19], any set of up to
users cannot determine the value of
.
Letting ![Q_{1}^{[\theta]},...,Q_{N}^{[\theta]}](https://s0.wp.com/latex.php?latex=Q_%7B1%7D%5E%7B%5B%5Ctheta%5D%7D%2C...%2CQ_%7BN%7D%5E%7B%5B%5Ctheta%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
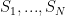
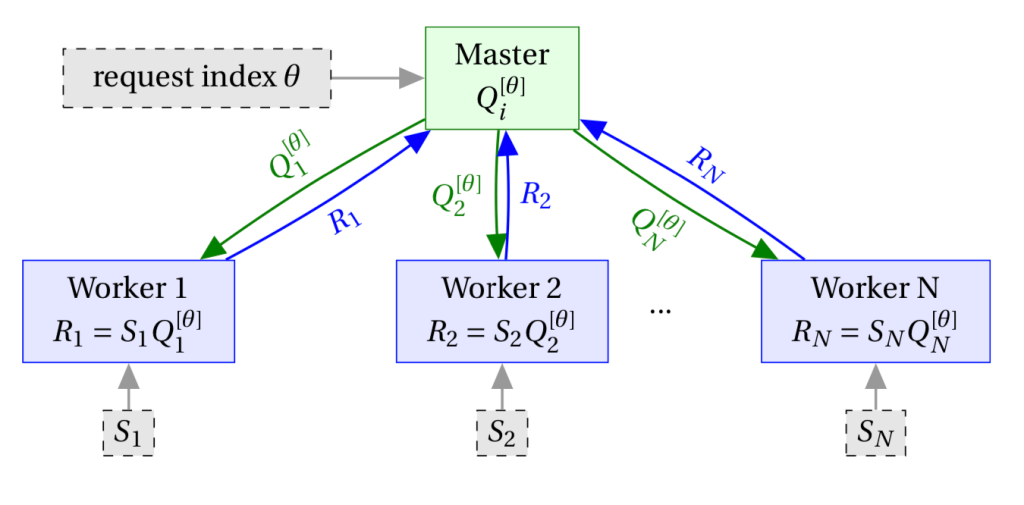
The information theoretic requirements of this system to be correct can be summarized as follows (using notation ![S_{[1:N]}](https://s0.wp.com/latex.php?latex=S_%7B%5B1%3AN%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
| Property | Information Theoretic Requirement |
| Data messages are size bits |  |
| Data messages are independent |  |
| Data can be determined from the stored information | ![H(W_1,....,W_K)|S_{[1:N]}) = 0](https://s0.wp.com/latex.php?latex=H%28W_1%2C....%2CW_K%29%7CS_%7B%5B1%3AN%5D%7D%29+%3D+0&bg=ffffff&fg=000000&s=0&c=20201002) |
| User has no prior knowledge of server data | ![I(S_{[1:N]};Q^{[\theta]}_{[1:N]},\theta) = 0](https://s0.wp.com/latex.php?latex=I%28S_%7B%5B1%3AN%5D%7D%3BQ%5E%7B%5B%5Ctheta%5D%7D_%7B%5B1%3AN%5D%7D%2C%5Ctheta%29+%3D+0&bg=ffffff&fg=000000&s=0&c=20201002) |
| X-Security |  , , ![\forall \mathcal{X}\subset [1:N],|\mathcal{X}|=X](https://s0.wp.com/latex.php?latex=%5Cforall+%5Cmathcal%7BX%7D%5Csubset+%5B1%3AN%5D%2C%7C%5Cmathcal%7BX%7D%7C%3DX&bg=ffffff&fg=000000&s=0&c=20201002) |
| T-Privacy | ![I(Q_{\mathcal{T}}^{[\theta]},S_{\mathcal{T}}; \theta) = 0,](https://s0.wp.com/latex.php?latex=I%28Q_%7B%5Cmathcal%7BT%7D%7D%5E%7B%5B%5Ctheta%5D%7D%2CS_%7B%5Cmathcal%7BT%7D%7D%3B+%5Ctheta%29+%3D+0%2C&bg=ffffff&fg=000000&s=0&c=20201002) ![\forall \mathcal{T} \subset [1:N], |\mathcal{T}|=T](https://s0.wp.com/latex.php?latex=%5Cforall+%5Cmathcal%7BT%7D+%5Csubset+%5B1%3AN%5D%2C+%7C%5Cmathcal%7BT%7D%7C%3DT&bg=ffffff&fg=000000&s=0&c=20201002) |
| Nodes answer only based on their data and received query | ![H(A_n^{[\theta]}| Q_n^{[\theta]},S_n) =0](https://s0.wp.com/latex.php?latex=H%28A_n%5E%7B%5B%5Ctheta%5D%7D%7C+Q_n%5E%7B%5B%5Ctheta%5D%7D%2CS_n%29+%3D0&bg=ffffff&fg=000000&s=0&c=20201002) |
| User can decode desired message from answers | ![H(W_{\theta} | A_{[1:N]}^{[\theta]},Q_{[1:N]}^{[\theta]} ,\theta) = 0](https://s0.wp.com/latex.php?latex=H%28W_%7B%5Ctheta%7D+%7C+A_%7B%5B1%3AN%5D%7D%5E%7B%5B%5Ctheta%5D%7D%2CQ_%7B%5B1%3AN%5D%7D%5E%7B%5B%5Ctheta%5D%7D+%2C%5Ctheta%29+%3D+0&bg=ffffff&fg=000000&s=0&c=20201002) |
Given these constraints, Jia et al. give bounds on the capacity of the system. Capacity is the maximum rate achievable, where rate is defined as bits requested by the worker (
If
then for arbitrary
,
.
When
:

[Jia, Sun, and Jafar ’19]


Jia et al. give schemes that achieve these bounds while preserving the privacy and security constraints by introducing random noise vectors into how data is stored and queries are constructed. The general scheme for 
For this scheme, the message length 
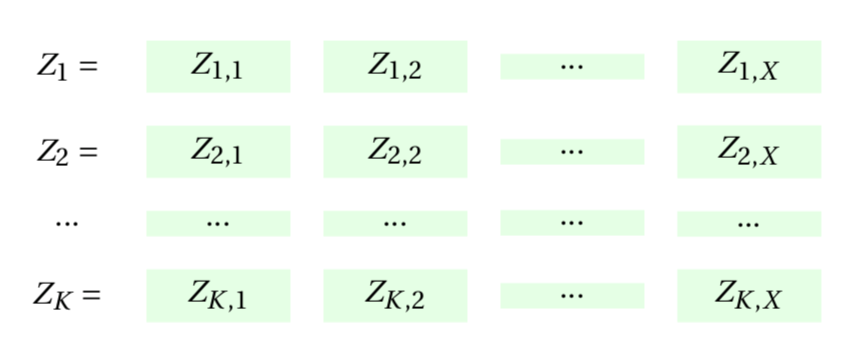
Next, apply an 


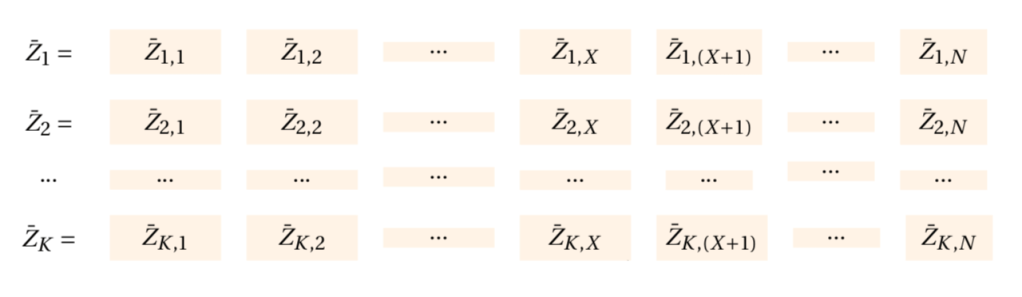
For our data 

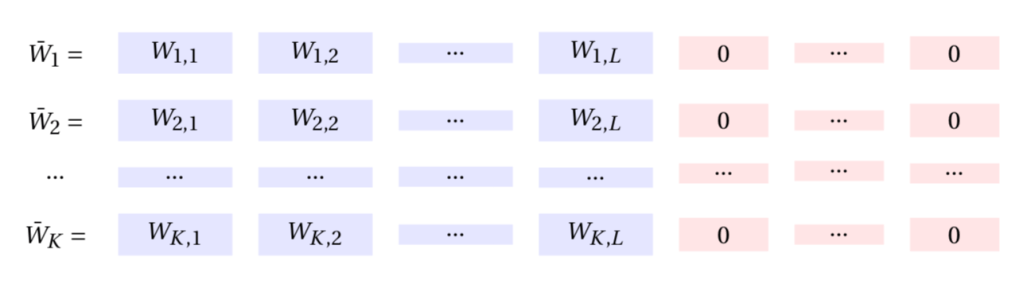
Now that the dimensions line up, we can add the two together and store each column 
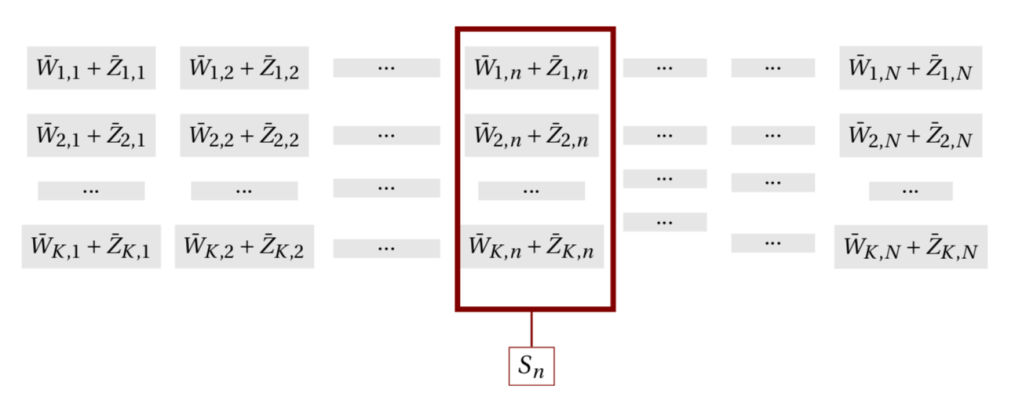
To access the data, the user downloads all 







Matrix Multiplication with Polynomial Codes
We now move on to the task of matrix-matrix multiplication. The methods for secure and private distributed matrix multiplication we will discuss shortly are based on polynomial codes, used by [Yu, Maddah-Ali, Avestimehr ’17] for doing distributed matrix multiplications robust to stragglers. Suppose the master has matrices 

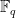





So to recover 
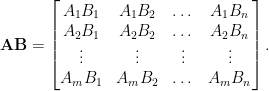
The key idea of polynomial codes is to encode 
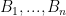


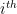
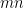

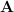
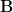
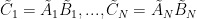
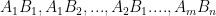
This idea is adapted by [Chang, Tandon ’18] to protect the data from colluding servers: noise is incorporated into the encodings such that the number of encoded matrices required to determine anything about the data is greater than the security threshold 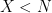


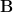


![D \in[1:M]](https://s0.wp.com/latex.php?latex=D+%5Cin%5B1%3AM%5D&bg=ffffff&fg=000000&s=0&c=20201002)

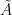

Chang and Tandon consider the following two privacy models, where up to 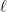
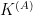

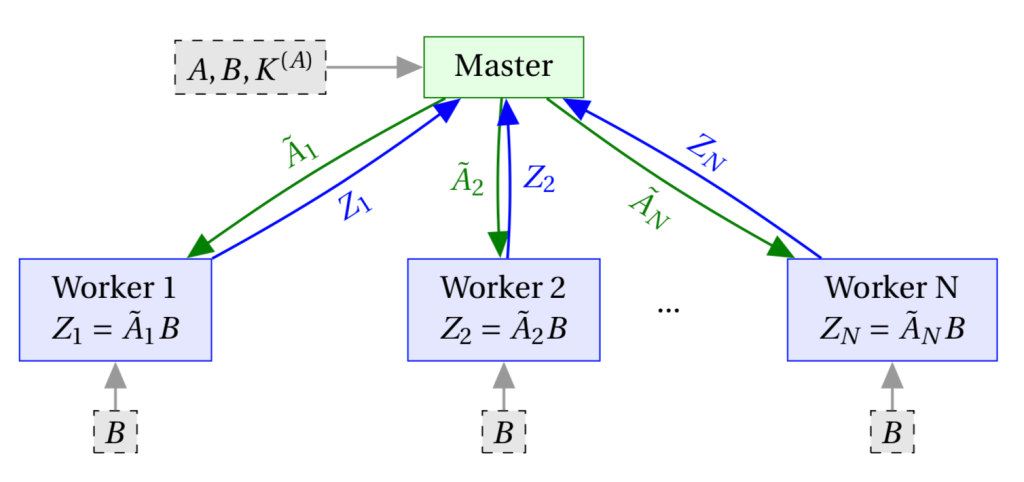
Both private:
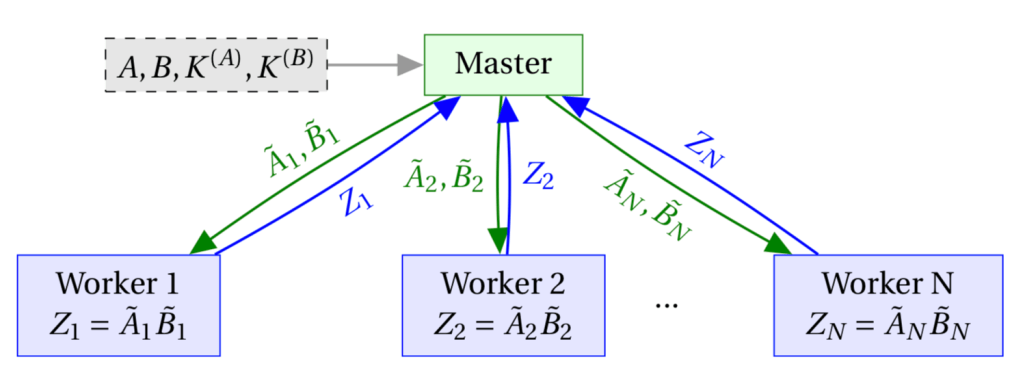
Kim, Yang, and Lee take a similar approach of applying the method of polynomial code to private matrix multiplication. As before, there are 
Since the master isn’t itself encoding 


![y^{(i)}_{[1:M]}](https://s0.wp.com/latex.php?latex=y%5E%7B%28i%29%7D_%7B%5B1%3AM%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
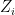

Conclusion
As we’ve seen, coding techniques originally designed to add redundancy and protect against data loss can also be used to intentionally incorporate noise for data protection. In particular, this can be done when out-sourcing matrix multiplications, making it a useful technique in many data processing and machine learning applications.
References:
- Jia, Zhuqing, Hua Sun, and Syed Ali Jafar. “Cross Subspace Alignment and the Asymptotic Capacity of X-Secure T-Private Information Retrieval.” IEEE Transactions on Information Theory 65.9 (2019): 5783-5798.
- Yu, Qian, Mohammad Maddah-Ali, and Salman Avestimehr. “Polynomial codes: an optimal design for high-dimensional coded matrix multiplication.” Advances in Neural Information Processing Systems. 2017.
- Chang, Wei-Ting, and Ravi Tandon. “On the capacity of secure distributed matrix multiplication.” 2018 IEEE Global Communications Conference (GLOBECOM). IEEE, 2018.
- Kim, Minchul, Heecheol Yang, and Jungwoo Lee. “Private Coded Matrix Multiplication.” IEEE Transactions on Information Forensics and Security (2019).

Leave a comment