
Automated Design of Error-Correcting Codes, Part 1

Introduction. For nearly a century, error-correcting codes (ECCs) have been used for allowing communication even when the used communication channel is corrupted by noise. Beyond communication, error-correcting codes have found a variety of other uses, from multiclass learning to even showing hardness of approximation. As such, understanding the rich world of error-correcting codes is essential for progress in all of these domains.
In our setting, imagine Alice wants to send a message to Bob of length 


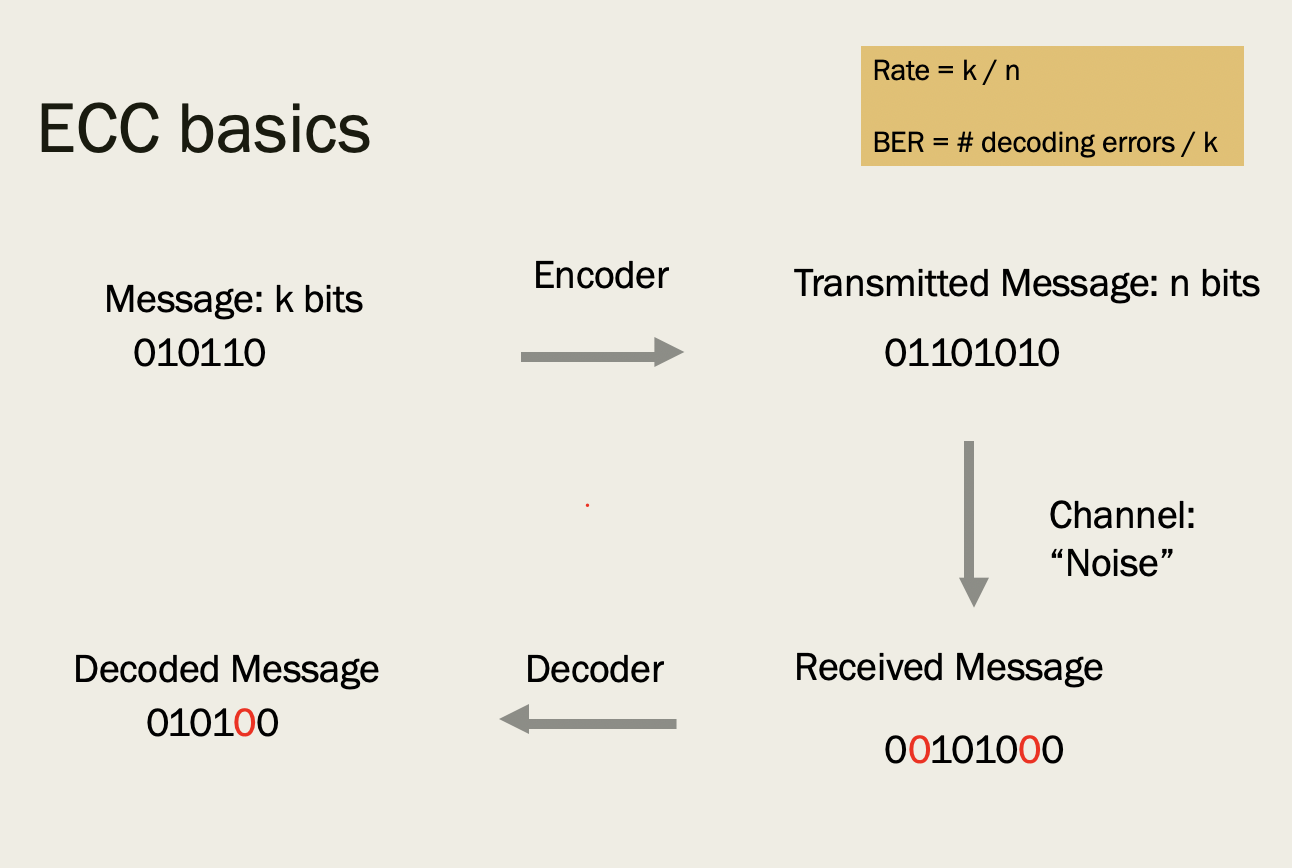
Basic ECC paradigm.
Since the days of Claude Shannon, many error-correcting codes have been discovered, such as Reed-Solomon codes and BCH codes. Each error-correcting code has its own tradeoffs (e.g., some have higher rate, some are more resistant to special kinds of channel corruptions, etc.). With the large number of ECCs which have been discovered, it can sometimes be overwhelming what the proper error correcting code is for a given application. Further, if the application is sufficiently specialized there may be no known ECC which meets your needs. Such concerns motivate the automation of error correcting codes, which is the main topic of this blog post.
I’m using the word “automation” to cover a variety of tasks which various computational methods could assist with in the study of ECCs:
- Existence — Does the code I want even exist?
- Encoding — What is the “best” way to convert my messages into a code?
- Decoding — How do I recover from noisy transmissions?
- Verification — Is the proposed ECC design provably correct?
- Selection — Which ECC from a given class should I use for a given application?
Each of these facets of the automation of ECCs is a whole field of research! In this and the subsequent post, I will discuss at a high level two types of techniques which have been used to approach these questions: “Formal Methods” and “Machine Learning.” We’ll cover formal methods in this post, and in the next post we will cover machine learning methods.
Formal Methods. The field of Formal Methods strives to give provable guarantees for various computational questions by reducing them to formal logic. Although formal methods are mostly used for software and hardware verification (that is, making sure they are “bug free”), such tools are also used by mathematicians to show the validity of mathematical statements that would be difficult to prove by hand. For example, the Kepler conjecture, a question of what is the best way to pack spheres in three dimensions–essentially finding an optimal error-correcting code in Euclidean space–was only firmly proved by Thomas Hales and his team through the use of automated theorem-proving tools.
A line of work for using formal methods to directly construct practical ECCs was initiated by Shamshiri and Cheng in 2010. In their work, they are motivated by designing error-correcting codes for static random-access memory (SRAM), the kind that is often used for CPU caches. When using SRAM (pictured below), a worry is that cosmic rays could hit some of the bits, causing them to flip. Further, it is not uncommon for a group of consecutive bits to flip. As such, it is desirable to esure that the error correcting code can correct either 

Static random-access memory (source: Wikipedia)
Assuming that the code to be construction is linear (the encoding map is a linear function over the field 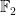



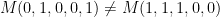


These Boolean constraints can be expressed in conjunctive normal form, i.e., a SAT instance. As such a SAT-solver can be used to determine if there exists a matrix M with the given properties for a given k and n. For instance, they are able to find an error correcting code with parameters 

Another line of work led by Ben Curtis (see the survey by Curtis, Kotsireas, and Ganesh) has been seeking to construct ECC-like combinatorial objects. An example of such an object is a Hadamard matrix: a square matrix with 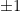
Formal Methods have further applications in error-correcting codes for distributed cloud storage and value-deviation-bounded codes.
This concludes our first post. In the next post, we discuss machine learning methods.
Are you aware of other examples or applications of automation to error-correcting codes? If so, please leave a comment.
Acknowledgments. I would like to thank my quals committee, Aviad Rubinstein, Moses Charikar, and Mary Wootters for valuable feedback.

{kind=link}
Leave a comment