I was excited to see “Approximating Edit Distance Within Constant Factor in Truly Sub-Quadratic Time” by Chakraborty, Das, Goldenberg, Koucky, and Saks in this year’s list of FOCS accepted papers. As you can guess from the title, their main result is a constant-factor approximation for edit distance in truly subquadratic time (i.e.  , for some constant
, for some constant  ). I spent quite a bit of time thinking about this problem in the past couple of years, and wiser people than me have spent much more time for a couple of decades. Congratulations!!
). I spent quite a bit of time thinking about this problem in the past couple of years, and wiser people than me have spent much more time for a couple of decades. Congratulations!!
Given strings  and
and  of
of  characters each, the textbook dynamic programming algorithm finds their edit distance in time
characters each, the textbook dynamic programming algorithm finds their edit distance in time 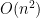 (if you haven’t seen this in your undergrad algorithms class, consider asking your university for a refund on your tuition). Recent complexity breakthroughs [1][2] show that under plausible assumptions like SETH, quadratic time is almost optimal for exact algorithms. This is too bad, because we like to compute edit distance between very long strings, like entire genomes of two organisms (see also this article in Quanta). There is a sequence of near-linear time algorithms with improved approximation factors [1][2][3][4], but until now the state of the art was polylogarithmic;
(if you haven’t seen this in your undergrad algorithms class, consider asking your university for a refund on your tuition). Recent complexity breakthroughs [1][2] show that under plausible assumptions like SETH, quadratic time is almost optimal for exact algorithms. This is too bad, because we like to compute edit distance between very long strings, like entire genomes of two organisms (see also this article in Quanta). There is a sequence of near-linear time algorithms with improved approximation factors [1][2][3][4], but until now the state of the art was polylogarithmic; actually for near-linear time, this is still the state of the art:
Open question 1: Is there a constant-factor approximation to edit distance that runs in near-linear time?
Update [5/2020]: Yay! A new near-linear time algorithm by Andoni and Nosatzki!
Algorithm sketch
Here is a sketch of an algorithm. It is somewhat different from the algorithm in the paper because I wrote this post before finding the full paper online.
Step 0: window-compatible matchings
We partition each string into  windows, or consecutive substrings of length
windows, or consecutive substrings of length  each. We then restrict our attention to window-compatible matchings: that is, instead of looking for the globally optimum way to transform to , we look for a partial matching between the – and -windows, and transform each -window to its matching -windows (unmatched -windows are deleted, and unmatched -windows are inserted). It turns out that restricting to window-compatible matchings is almost without loss of generality.
each. We then restrict our attention to window-compatible matchings: that is, instead of looking for the globally optimum way to transform to , we look for a partial matching between the – and -windows, and transform each -window to its matching -windows (unmatched -windows are deleted, and unmatched -windows are inserted). It turns out that restricting to window-compatible matchings is almost without loss of generality.
In order to find the optimum window-compatible matching, we can find the distances between every pair of windows, and then use a (weighted) dynamic program of size 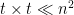 . The reason I call it “Step 0” is because so far we made zero progress on running time: we still have to compute the edit distance between
. The reason I call it “Step 0” is because so far we made zero progress on running time: we still have to compute the edit distance between  pairs, and each computation takes time
pairs, and each computation takes time  , so
, so 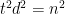 time in total.
time in total.
Approximating all the pairwise distances reduces to the following problem: given threshold 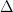 , compute the bipartite graph
, compute the bipartite graph  over the windows, where two windows
over the windows, where two windows  and
and  share an edge if
share an edge if  . In fact it suffices to compute an approximate
. In fact it suffices to compute an approximate 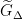 , where and may share an edge even if their edit distance is a little more than .
, where and may share an edge even if their edit distance is a little more than .
New Goal: Compute faster than naively computing all pairwise edit distances.
Step 1: sparsifying
While there are many edges in  , say average degree
, say average degree  : Draw a random edge
: Draw a random edge  , and let
, and let  be two other neighbors of
be two other neighbors of 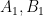 , respectively. Applying the triangle inequality (twice), we have that
, respectively. Applying the triangle inequality (twice), we have that  , so we can immediately add
, so we can immediately add  to . In expectation, have neighbors each, so we discovered a total of
to . In expectation, have neighbors each, so we discovered a total of  pairs; of which we expect that roughly
pairs; of which we expect that roughly  correspond to new edges in . Repeat at most
correspond to new edges in . Repeat at most  times until we discovered almost all the edges in . Notice that each iteration took us
times until we discovered almost all the edges in . Notice that each iteration took us 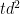 time (computing all the edit distances from
time (computing all the edit distances from  and
and  ); hence in total only
); hence in total only  . Thus we reduced to the sparse case in truly subquadratic time.
. Thus we reduced to the sparse case in truly subquadratic time.
The algorithm up to this point is actually due to a recent paper by Boroujeni et al; for the case when is relatively sparse, they use Grover Search to discover all the remaining edges in quantum subquadratic time. It remains to see how to do it classically…
Step 2: when is relatively sparse
The main observation we need for this part is that if windows and  are close, then in an optimum window-compatible matching they are probably not matched to -windows that are very far apart. And in the rare event that they are matched to far-apart -windows, the cost of inserting so many characters between and outweighs the cost of completely replacing if we had to. So once we have a candidate list of -windows that might match to, it is safe to only search for good matches for around each of those candidates. But when the graph is sparse, we have such a short list: the neighbors of !
are close, then in an optimum window-compatible matching they are probably not matched to -windows that are very far apart. And in the rare event that they are matched to far-apart -windows, the cost of inserting so many characters between and outweighs the cost of completely replacing if we had to. So once we have a candidate list of -windows that might match to, it is safe to only search for good matches for around each of those candidates. But when the graph is sparse, we have such a short list: the neighbors of !
We have to be a bit careful: for example, it is possible that is not matched to any of its neighbors in . But if we sample enough ‘s from some interval around , then either (i) at least one of them is matched to a neighbor in ; or (ii) doesn’t contribute much to reducing the edit distance for this interval, so it’s OK to miss some of those edges.
Improving the approximation factor
On the back of my virtual envelope, I think the above ideas give a  -approximation. But as far as genomes go, up to a -approximation, you’re as closely related to your dog as to a banana. So it would be great to improve the approximation factor:
-approximation. But as far as genomes go, up to a -approximation, you’re as closely related to your dog as to a banana. So it would be great to improve the approximation factor:
Open question 2: Is there a  -approximation algorithm for edit distance in truly subquadratic (or near-linear) time?
-approximation algorithm for edit distance in truly subquadratic (or near-linear) time?
Note that only the sparsification step loses more than in approximation. Also, none of the existing fine-grained hardness results rule out an -approximation, even in linear time!



A related open problem (that is arguably more relevant to practice than computing the edit distance, see, e.g., [1]) is the approximate nearest neighbor search for the edit distance. The only known way to do it (in the worst case, there are some decent heuristics) is to embed the edit distance into l_1 [2] and use locality-sensitive hashing. This gives approximation 2^{sqrt{log d log log d}}, where d is the length of strings. Can one improve it to poly(log d)? To O(1)?
[1] https://arxiv.org/abs/1702.00093
[2] http://www.cs.technion.ac.il/~rabani/Papers/OstrovskyR-JACM-revised.pdf
LikeLiked by 1 person
Thanks Ilya! Embarrassingly, the state-of-the-art conditional hardness result for approximate nearest neighbor with edit distance metric also goes through (and thus only gives hardness for a tiny
(and thus only gives hardness for a tiny  -factor.
-factor.
LikeLiked by 1 person
Indeed, the edit distance contains a copy of l_1, but we currently have *no* evidence that ANN for edit distance is harder than for l_1. As our framework [1] suggests, the heart of the matter is to understand how well shortest-path metrics of expander graphs embed into the edit distance.
More precisely, it would be great to show that the cutting modulus (in the sense of a short document [2]) of {0, 1}^d equipped with the edit distance is poly(log d). I think it should be true.
[1] https://ilyaraz.org/static/papers/spectral_gap.pdf
[2] https://ilyaraz.org/static/misc/cutting_modulus.pdf
LikeLike
Wow! Thanks Aviad for the the nice blog post on this. In hindsight it looks our SODA’18 paper: was so close — missing only that last step.
LikeLiked by 1 person