
Quantum DNA sequencing & the ultimate hardness hypothesis

Longest common subsequence (LCS) and edit distance (ED) are fundamental similarity measures of interest to genomic applications (insertions/deletions/substitutions are a pretty good proxy for both mutations and read errors). The fastest known algorithms for computing the LCS/ED between two 

Quantum algorithms for edit distance?
One way to try to circumvent the computational barriers is by approximation algorithms (see my blog post). A different approach is to go with quantum algorithms: Grover’s search can solve NC-SAT in 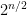
Alas, even with the power of quantum computers we don’t know any truly subquadratic algorithms for computing LCS/ED. On the other hand, it is not clear how to rule out even linear-time algorithms. A few weeks ago, Buhrman, Patro, and Speelman, posted a paper that gives a 
Open Problem: Close the
gap for quantum query complexity of ED/LCS.
What is “query complexity” of ED/LCS? Buhrman et al. consider the following query model: In LCS, we want a maximum monotone matching between the characters of the two strings, where we can match two characters if they’re identical. Now suppose that in the query complexity problem we still want to find a maximum monotone matching, but instead of the character-equality graph (which is a union of disjoint cliques), we have an arbitrary bipartite graph, and given a pair of vertices, the oracle tells you if there is an edge between them.
This model may seem a bit counter-intuitive at first since the graphs may not correspond to any pair of strings; and indeed other models have been considered before [UAH76][AKO10]. But it turns out that this model is well-motivated by the NC-SETH lower bound (see discussion below).
The ultimate hardness hypothesis
What does the
[Ultimate Hardness Hypothesis] For every problem, the white-box computational complexity is lower bounded by the black-box query complexity.”
In communication complexity similar statements are known and are called simulation/lifting theorems (see e.g. Mika’s thesis). For computational complexity, there are obvious counter examples such as “decide if the oracle can be implemented by a small circuit”. So it only makes sense to continue to assume the ultimate hardness hypothesis for “reasonable problems” instead of “every problem”.
But Burhman et al. identify the following variant of the ultimate hardness hypothesis which I find very interesting. It is defined with respect to a function 
[Burhman et al.-QSETH, paraphrased] For every
, deciding if
At a first read, I thought that arguments a-la impossibility of obfuscation [BGI+01] should refute this hypothesis, but a few weeks later I still don’t know how to prove it. Do you?
A tip for the upcoming holidays
During my postdoc, I worked on the quantum query complexity of ED/LCS with Shalev Ben-David, Rolando La Placa, and John Wright. I was a bit bummed to find out that we got scooped by Buhrman et al, but I know of at least 3 other groups that were also scooped by the same paper, so at least we’re in good company 🙂
At the time, a fellow postdoc from Psychology asked me what I was working on. I resisted the temptation to try to explain the various quantum variants of NC-SETH, and instead told him I was working on “DNA sequencing with quantum computers”. His reaction was priceless. Regardless of what you’re actually working on, try this line during the holidays when your relatives ask you about your work.

Leave a comment