
Charles Stein was one of the most active and influential Statisticians of the past century, with a career spanning seven decades including over sixty year as a professor in Stanford’s Statistics Department. Since his passing nearly a year ago, I have been meaning to write a blog post for the TCS audience describing some of his contributions that are relevant to our community. Rather than attempting to summarize all of the influences that his work has had on the theory community, I’ll focus on just one: an approach to proving central-limit theorems (and bounds on the rate of convergence of such theorems) referred to as Stein’s Method, which I have used in some of my work. Among the many different approaches to proving central-limit style theorems, Stein’s Method stands out as one of the most conceptually elegant, and versatile approaches. Indeed, Stein’s method lends itself to many settings where we wish to analyzing sums of dependent random variables, settings with high-dimensional random variables, and settings where we hope to prove convergence to non-Gaussian distributions.
Recall the setting of the most basic central limit theorem: Suppose 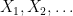 are independent identical random variables, of mean 0 and variance 1, then
are independent identical random variables, of mean 0 and variance 1, then  converges (in a sense that we will make explicit later) to a standard Gaussian distribution as
converges (in a sense that we will make explicit later) to a standard Gaussian distribution as  goes to infinity.
goes to infinity.
What is the usual way of bounding the rate at which convergence occurs? One approach, known as the Lindeberg or hybridization method, is to iteratively replace each  with a standard Gaussian, and bound the effect that each of these substitutions incurs. Another standard approach is to note that the density function of the sum or independent random variables is the convolution of their density functions, and hence the Fourier transform of the density of the sum is the product of the densities, and directly analyze the distance to the Fourier transform of the Gaussian (which is Gaussian!). Both of these approaches, however, seem to rely heavily on the independence of the
with a standard Gaussian, and bound the effect that each of these substitutions incurs. Another standard approach is to note that the density function of the sum or independent random variables is the convolution of their density functions, and hence the Fourier transform of the density of the sum is the product of the densities, and directly analyze the distance to the Fourier transform of the Gaussian (which is Gaussian!). Both of these approaches, however, seem to rely heavily on the independence of the  .
.
The usual starting place in describing Stein’s Method is the fact that, for a Gaussian random variable,  , for any (differentiable) function
, for any (differentiable) function  ,
, ![\mathbb{E}[f'(Z)-Zf(Z)] = 0](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5Bf%27%28Z%29-Zf%28Z%29%5D+%3D+0&bg=ffffff&fg=000000&s=0&c=20201002) , where
, where  denotes the derivative of . Furthermore, if a random variable satisfies this equation for all functions , then it is a standard Gaussian! The idea is then to argue that, for any random variable
denotes the derivative of . Furthermore, if a random variable satisfies this equation for all functions , then it is a standard Gaussian! The idea is then to argue that, for any random variable  , the extent to which
, the extent to which ![\mathbb{E}[f'(X)-Zf(X)]](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5Bf%27%28X%29-Zf%28X%29%5D&bg=ffffff&fg=000000&s=0&c=20201002) is not zero can be related to how far is from Gaussian. An easy integration will establish the fact that a Gaussian satisfies this equation (and is the only distribution satisfying it). Before continuing further down this path, we will take a step back and see a more geometric (and enlightening) explanation for why . This alternate viewpoint will also also provide a more general framing of Stein’s method that provides some indication of why we might expect Stein’s method to be so adaptable to different settings.
is not zero can be related to how far is from Gaussian. An easy integration will establish the fact that a Gaussian satisfies this equation (and is the only distribution satisfying it). Before continuing further down this path, we will take a step back and see a more geometric (and enlightening) explanation for why . This alternate viewpoint will also also provide a more general framing of Stein’s method that provides some indication of why we might expect Stein’s method to be so adaptable to different settings.
At the highest level, Stein’s Method can be thought of as the following general recipe: Suppose you want to show that some distribution,  , is close to some “nice” distribution,
, is close to some “nice” distribution,  .
.
- Find a transformation (a mapping from distributions to distributions),
 , for which is the unique fixed point.
, for which is the unique fixed point.
- Next, show that the amount by which a distribution is changed by applying is related to the distance between the distribution and . [As a sanity check, the distance from to itself is 0, and
 .]
.]
- Finally, apply to the distribution we care about, and watch closely and see how much it is changed.
Crucially, the above approach turns the problem of comparing directly to , into the problem of comparing to a transformed version of , namely 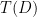 . This is one of the main reasons for the versatility of Stein’s Method. While it shouldn’t be obvious why it is often easier to compare to than to directly compare to , a conceptual explanation is that comparing and lets one keep whatever complicated structure exists in —for example if is a sum of dependent random variables, one might not need to disentangle these dependencies in order to make this comparison. Furthermore, as we will see, we actually won’t even need to transform , we can instead simply transform the lens that we are using to view the distribution, namely transforming the set of “test functions” that correspond to the metric in which we are hoping to similarity between and .
. This is one of the main reasons for the versatility of Stein’s Method. While it shouldn’t be obvious why it is often easier to compare to than to directly compare to , a conceptual explanation is that comparing and lets one keep whatever complicated structure exists in —for example if is a sum of dependent random variables, one might not need to disentangle these dependencies in order to make this comparison. Furthermore, as we will see, we actually won’t even need to transform , we can instead simply transform the lens that we are using to view the distribution, namely transforming the set of “test functions” that correspond to the metric in which we are hoping to similarity between and .
Lets now unpack this very general recipe in the case that is a Gaussian. What is a transformation that has the standard Gaussian as a fixed point? There are many possibilities, but lets consider the transformation that consists of adding a small amount of Gaussian “noise” (i.e. convolving the density by a tiny Gaussian), and then linearly rescaling the distribution so that the variance of a univariate distribution with zero mean is left unchanged. This transformation is equally valid in the multivariate setting, but lets focus on distributions over  . Concretely, let
. Concretely, let  be the transformation that maps to the distribution corresponding to the random variable
be the transformation that maps to the distribution corresponding to the random variable  , where is drawn from , and
, where is drawn from , and  is an independent random variable drawn from
is an independent random variable drawn from 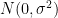 . Since the sum of independent Gaussians is Gaussian, and the variance of the sum of independent random variables is the sum of the variances,
. Since the sum of independent Gaussians is Gaussian, and the variance of the sum of independent random variables is the sum of the variances,  where is the standard Gaussian. And it is not hard to see that is the unique fixed point of this transformation.
where is the standard Gaussian. And it is not hard to see that is the unique fixed point of this transformation.
The connection between this transformation and the fact that ![\mathbb{E}[f'(Z)-Zf(Z)]=0](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5Bf%27%28Z%29-Zf%28Z%29%5D%3D0&bg=ffffff&fg=000000&s=0&c=20201002) for any function if is a standard Gaussian random variables come from considering the transformation
for any function if is a standard Gaussian random variables come from considering the transformation 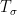 as
as 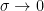 . [This infinitesimal transformation, when iteratively applied and viewed as a process, is known as the Ornstein-Uhlenbeck process.] For a function
. [This infinitesimal transformation, when iteratively applied and viewed as a process, is known as the Ornstein-Uhlenbeck process.] For a function  , consider how
, consider how ![\mathbb{E}[g(X)]](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5Bg%28X%29%5D&bg=ffffff&fg=000000&s=0&c=20201002) changes if we apply this infinitesimal transformation to . We can directly analyze the effect of the two components of
changes if we apply this infinitesimal transformation to . We can directly analyze the effect of the two components of  , namely the addition of Gaussian noise, and then the rescaling by a factor of
, namely the addition of Gaussian noise, and then the rescaling by a factor of  . To analyze this first component, note that if
. To analyze this first component, note that if  is distributed according to
is distributed according to 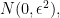 then, to first order,
then, to first order, ![\mathbb{E}[g(X + Z_{\epsilon})] \approx \mathbb{E}[g(X)] +\frac{\epsilon^2}{2}\mathbb{E}[g''(Z)]](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5Bg%28X+%2B+Z_%7B%5Cepsilon%7D%29%5D+%5Capprox+%5Cmathbb%7BE%7D%5Bg%28X%29%5D+%2B%5Cfrac%7B%5Cepsilon%5E2%7D%7B2%7D%5Cmathbb%7BE%7D%5Bg%27%27%28Z%29%5D&bg=ffffff&fg=000000&s=0&c=20201002) . As a sanity check, if is linear, than this zero-mean noise will have no effect on the expectation, and if has positive second derivative, this noise will increase the expectation. To analyze the second component, the scaling of by a factor of
. As a sanity check, if is linear, than this zero-mean noise will have no effect on the expectation, and if has positive second derivative, this noise will increase the expectation. To analyze the second component, the scaling of by a factor of 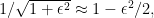 note that this will change by
note that this will change by 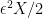 , and hence, to first order, this will alter the expectation by
, and hence, to first order, this will alter the expectation by ![\frac{\epsilon^2}{2}\mathbb{E}[Xg'(X)]](https://s0.wp.com/latex.php?latex=%5Cfrac%7B%5Cepsilon%5E2%7D%7B2%7D%5Cmathbb%7BE%7D%5BXg%27%28X%29%5D&bg=ffffff&fg=000000&s=0&c=20201002) . Putting these two pieces together yields that for any random variable, ,
. Putting these two pieces together yields that for any random variable, ,
![\mathbb{E}[g(T_{\epsilon}(X)] \approx \mathbb{E}[g(X) + \frac{\epsilon^2}{2} g''(X) - \frac{\epsilon^2}{2} X g'(X)].](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5Bg%28T_%7B%5Cepsilon%7D%28X%29%5D+%5Capprox+%5Cmathbb%7BE%7D%5Bg%28X%29+%2B+%5Cfrac%7B%5Cepsilon%5E2%7D%7B2%7D+g%27%27%28X%29+-+%5Cfrac%7B%5Cepsilon%5E2%7D%7B2%7D+X+g%27%28X%29%5D.&bg=ffffff&fg=000000&s=0&c=20201002)
Hence, from the viewpoint of a function , the amount by which the transformation alters the random variable is proportional to ![\mathbb{E}[g''(X)]-\mathbb{E}[Xg'(X)].](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5Bg%27%27%28X%29%5D-%5Cmathbb%7BE%7D%5BXg%27%28X%29%5D.&bg=ffffff&fg=000000&s=0&c=20201002) And, if
And, if  is a standard Gaussian random variable, then we know this transformation preserves the distribution of , and hence
is a standard Gaussian random variable, then we know this transformation preserves the distribution of , and hence ![\mathbb{E}[g''(Z)]-\mathbb{E}[Xg'(Z)] = 0](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5Bg%27%27%28Z%29%5D-%5Cmathbb%7BE%7D%5BXg%27%28Z%29%5D+%3D+0&bg=ffffff&fg=000000&s=0&c=20201002) . Letting the function denote
. Letting the function denote 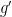 , we have re-derived the fact that
, we have re-derived the fact that ![\mathbb{E}[f'(Z) - Z f(Z)]=0](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5Bf%27%28Z%29+-+Z+f%28Z%29%5D%3D0&bg=ffffff&fg=000000&s=0&c=20201002) via a completely intuitive argument!!
via a completely intuitive argument!!
Our central limit theorems will now come from analyzing the quantity ![\mathbb{E}[g''(X)]-\mathbb{E}[Xg'(X)]](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5Bg%27%27%28X%29%5D-%5Cmathbb%7BE%7D%5BXg%27%28X%29%5D&bg=ffffff&fg=000000&s=0&c=20201002) for all functions belonging to some set that depends on the distance metric in question. (And, of course, we might as well drop one of the differentiations). Suppose we would like to prove that
for all functions belonging to some set that depends on the distance metric in question. (And, of course, we might as well drop one of the differentiations). Suppose we would like to prove that 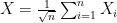 is close to the standard Gaussian, according to some specific metric. For some family of test functions,
is close to the standard Gaussian, according to some specific metric. For some family of test functions,  , suppose we wish to analyze
, suppose we wish to analyze ![d_{H}(X,Z) = \sup_{h \in H} \left( \mathbb{E}_{X}[h(X)] - \mathbb{E}_Z [h(Z)]\right)](https://s0.wp.com/latex.php?latex=d_%7BH%7D%28X%2CZ%29+%3D+%5Csup_%7Bh+%5Cin+H%7D+%5Cleft%28+%5Cmathbb%7BE%7D_%7BX%7D%5Bh%28X%29%5D+-+%5Cmathbb%7BE%7D_Z+%5Bh%28Z%29%5D%5Cright%29&bg=ffffff&fg=000000&s=0&c=20201002) . If consists of the set of functions that are indicators of measurable sets, then
. If consists of the set of functions that are indicators of measurable sets, then 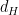 is total variation distance (
is total variation distance ( distance). If consists of all indicators of half-lines, then the corresponding distance metric is the distance between the cumulative distribution functions, as in the usual Berry-Esseen bound. If is the set of all Lipschitz-1 functions, then the distance metric corresponds to Wasserstein distance (also referred to as earth-mover distance). Stein’s method can be made to work for many distance metrics, though it is especially easy to work with Wasserstein distance, as the continuity of the test functions play well with the differentiation, etc.
distance). If consists of all indicators of half-lines, then the corresponding distance metric is the distance between the cumulative distribution functions, as in the usual Berry-Esseen bound. If is the set of all Lipschitz-1 functions, then the distance metric corresponds to Wasserstein distance (also referred to as earth-mover distance). Stein’s method can be made to work for many distance metrics, though it is especially easy to work with Wasserstein distance, as the continuity of the test functions play well with the differentiation, etc.
So how do we actually get a CLT out of this all? How can we relate the distance between the distribution of and a Gaussian to some expression involving the quantity ![\mathbb{E}[f'(X)]-\mathbb{E}[Xf(X)]](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5Bf%27%28X%29%5D-%5Cmathbb%7BE%7D%5BXf%28X%29%5D&bg=ffffff&fg=000000&s=0&c=20201002) ? Given a function
? Given a function  , we can attempt to solve the differentiable equation:
, we can attempt to solve the differentiable equation: ![f'(x) - xf(x) = h(x) - \mathbb{E}[h(Z)].](https://s0.wp.com/latex.php?latex=f%27%28x%29+-+xf%28x%29+%3D+h%28x%29+-+%5Cmathbb%7BE%7D%5Bh%28Z%29%5D.&bg=ffffff&fg=000000&s=0&c=20201002) Note that the expectation of the right side of this equation, for
Note that the expectation of the right side of this equation, for  distributed according to , is precisely the difference in expectations that we would like to analyze, and the left side is the equation that we know is 0 in expectation if is distributed according to , and which will tell us how far is from Z. This differential equation is fairly easy to solve for , yielding the solution:
distributed according to , is precisely the difference in expectations that we would like to analyze, and the left side is the equation that we know is 0 in expectation if is distributed according to , and which will tell us how far is from Z. This differential equation is fairly easy to solve for , yielding the solution:
![f_h(x) = e^{x^2}/2 \int_{\-\infty}^x \left(h(t)-\mathbb{E}[h(Z)]\right)e^{-t^2/2} dt.](https://s0.wp.com/latex.php?latex=f_h%28x%29+%3D+e%5E%7Bx%5E2%7D%2F2+%5Cint_%7B%5C-%5Cinfty%7D%5Ex+%5Cleft%28h%28t%29-%5Cmathbb%7BE%7D%5Bh%28Z%29%5D%5Cright%29e%5E%7B-t%5E2%2F2%7D+dt.&bg=ffffff&fg=000000&s=0&c=20201002)
Hence, we have now established that ![d_H(X,Z) = \sup_{h \in H} \left(\mathbb{E}[h(X)]-\mathbb{E}[h(Z)] \right)= \sup_{h \in H} \left( \mathbb{E}[f'_h(X)-Xf_h(X)]\right).](https://s0.wp.com/latex.php?latex=d_H%28X%2CZ%29+%3D+%5Csup_%7Bh+%5Cin+H%7D+%5Cleft%28%5Cmathbb%7BE%7D%5Bh%28X%29%5D-%5Cmathbb%7BE%7D%5Bh%28Z%29%5D+%5Cright%29%3D+%5Csup_%7Bh+%5Cin+H%7D+%5Cleft%28+%5Cmathbb%7BE%7D%5Bf%27_h%28X%29-Xf_h%28X%29%5D%5Cright%29.&bg=ffffff&fg=000000&s=0&c=20201002)
To finish, we leverage the properties of , together with an understanding of how  is related to to bound the quantity on the right side. In the case that
is related to to bound the quantity on the right side. In the case that  for i.i.d. ‘s, this will be a three line argument where we compute the linear Taylor expansions of
for i.i.d. ‘s, this will be a three line argument where we compute the linear Taylor expansions of  and
and 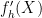 about
about 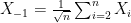 :
:
![\mathbb{E}[Xf_h(X)]=\mathbb{E}[n\frac{1}{\sqrt{n}}X_1 f_h(X)]=\frac{1}{\sqrt{n}} \mathbb{E}[X_1 f_h(\frac{1}{\sqrt{n}}X_1 + X_{-1})]](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5BXf_h%28X%29%5D%3D%5Cmathbb%7BE%7D%5Bn%5Cfrac%7B1%7D%7B%5Csqrt%7Bn%7D%7DX_1+f_h%28X%29%5D%3D%5Cfrac%7B1%7D%7B%5Csqrt%7Bn%7D%7D+%5Cmathbb%7BE%7D%5BX_1+f_h%28%5Cfrac%7B1%7D%7B%5Csqrt%7Bn%7D%7DX_1+%2B+X_%7B-1%7D%29%5D&bg=ffffff&fg=000000&s=0&c=20201002)
![= \frac{1}{\sqrt{n}} \mathbb{E}[X_1 f_h(\frac{1}{\sqrt{n}}X_1 + X_{-1})]](https://s0.wp.com/latex.php?latex=%3D+%5Cfrac%7B1%7D%7B%5Csqrt%7Bn%7D%7D+%5Cmathbb%7BE%7D%5BX_1+f_h%28%5Cfrac%7B1%7D%7B%5Csqrt%7Bn%7D%7DX_1+%2B+X_%7B-1%7D%29%5D&bg=ffffff&fg=000000&s=0&c=20201002)
![= \sqrt{n} \mathbb{E}\left[X_1 \left(f_h(X_{-1}) + \frac{1}{\sqrt{n}}X_1f'_h(X_{-1})\right)\right] + err_1,](https://s0.wp.com/latex.php?latex=%3D%C2%A0+%5Csqrt%7Bn%7D+%5Cmathbb%7BE%7D%5Cleft%5BX_1+%5Cleft%28f_h%28X_%7B-1%7D%29+%2B+%5Cfrac%7B1%7D%7B%5Csqrt%7Bn%7D%7DX_1f%27_h%28X_%7B-1%7D%29%5Cright%29%5Cright%5D+%2B+err_1%2C&bg=ffffff&fg=000000&s=0&c=20201002)
where 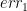 is the error term in the linear approximation, and is bounded in magnitude by
is the error term in the linear approximation, and is bounded in magnitude by ![|err_1| \le \frac{1}{\sqrt{n}}\mathbb{E}[|X_1|^3] \|f''_h\|.](https://s0.wp.com/latex.php?latex=%7Cerr_1%7C+%5Cle+%5Cfrac%7B1%7D%7B%5Csqrt%7Bn%7D%7D%5Cmathbb%7BE%7D%5B%7CX_1%7C%5E3%5D+%5C%7Cf%27%27_h%5C%7C.&bg=ffffff&fg=000000&s=0&c=20201002) Leveraging the independence of
Leveraging the independence of  and
and  , and the assumption that has zero mean and unit variance, the above simplifies to
, and the assumption that has zero mean and unit variance, the above simplifies to ![\mathbb{E}[f'_h(X_{-1})] + err_1](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5Bf%27_h%28X_%7B-1%7D%29%5D+%2B+err_1&bg=ffffff&fg=000000&s=0&c=20201002) . We now analyze the second term,
. We now analyze the second term, ![\mathbb{E}[f'_h(X)],](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5Bf%27_h%28X%29%5D%2C&bg=ffffff&fg=000000&s=0&c=20201002) via a similar expansion:
via a similar expansion:
![\mathbb{E}[f'_h(X)] = \mathbb{E}[f'_h(X_{-1}+\frac{1}{\sqrt{n}}X_1)] = \mathbb{E}[f'_h[X_{-1}]+err_2,](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5Bf%27_h%28X%29%5D+%3D+%5Cmathbb%7BE%7D%5Bf%27_h%28X_%7B-1%7D%2B%5Cfrac%7B1%7D%7B%5Csqrt%7Bn%7D%7DX_1%29%5D+%3D+%5Cmathbb%7BE%7D%5Bf%27_h%5BX_%7B-1%7D%5D%2Berr_2%2C&bg=ffffff&fg=000000&s=0&c=20201002)
where  is bounded in magnitude as
is bounded in magnitude as ![|err_2| \le \frac{1}{\sqrt{n}}\mathbb{E}[|X_1|] \|f''_h\|.](https://s0.wp.com/latex.php?latex=%7Cerr_2%7C+%5Cle+%5Cfrac%7B1%7D%7B%5Csqrt%7Bn%7D%7D%5Cmathbb%7BE%7D%5B%7CX_1%7C%5D+%5C%7Cf%27%27_h%5C%7C.&bg=ffffff&fg=000000&s=0&c=20201002) Combining these expressions, we have established the following:
Combining these expressions, we have established the following:
![d_H(X,Z) = \sum_{h \in H}\left(\mathbb{E}[h(X)]-\mathbb{E}[h(Z)] \right) =\sum_{h \in H}\left( \mathbb{E}[f'_h(X)]-\mathbb{E}[Xf_h(X)] \right)](https://s0.wp.com/latex.php?latex=d_H%28X%2CZ%29+%3D+%5Csum_%7Bh+%5Cin+H%7D%5Cleft%28%5Cmathbb%7BE%7D%5Bh%28X%29%5D-%5Cmathbb%7BE%7D%5Bh%28Z%29%5D+%5Cright%29+%3D%5Csum_%7Bh+%5Cin+H%7D%5Cleft%28+%5Cmathbb%7BE%7D%5Bf%27_h%28X%29%5D-%5Cmathbb%7BE%7D%5BXf_h%28X%29%5D+%5Cright%29&bg=ffffff&fg=000000&s=0&c=20201002)
![\le \sup_{h \in H} \frac{\|f''_h\|}{\sqrt{n}}(1+\mathbb{E}[|X_1|^3]).](https://s0.wp.com/latex.php?latex=%5Cle+%5Csup_%7Bh+%5Cin+H%7D+%5Cfrac%7B%5C%7Cf%27%27_h%5C%7C%7D%7B%5Csqrt%7Bn%7D%7D%281%2B%5Cmathbb%7BE%7D%5B%7CX_1%7C%5E3%5D%29.&bg=ffffff&fg=000000&s=0&c=20201002)
If is the class of indicators of half-lines, then we will need to work a bit harder to get a nice bound out of this expression. If, however, we care about Wasserstein distance, it is not hard to show that for any Lipschitz function , 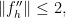 in which case this immediately yields the familiar
in which case this immediately yields the familiar  error bound for our central limit theorem!
error bound for our central limit theorem!
For many other settings where one might wish to prove convergence bounds for central limit theorems, Stein’s method takes roughly the same form as the above argument. The multivariate analog proceeds along essentially the same route, beginning with the observation that the Gaussian is the unique fixed point for the multivariate analog of the transformation described above. To show convergence to a non-Gaussian distribution, the same model can also be applied. For example, to show convergence to a Poisson distribution of expectation  , rather than using the expression
, rather than using the expression 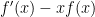 (which is the “characterizing operator” for the standard Gaussian distribution), one instead considers
(which is the “characterizing operator” for the standard Gaussian distribution), one instead considers 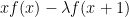 , as the expectation of this expression is zero for every function if, and only if, is drawn from a Poisson distribution of expectation .
, as the expectation of this expression is zero for every function if, and only if, is drawn from a Poisson distribution of expectation .
This blog post only begins to describe the tip of the elegant, deep, and multifaceted iceberg that is Stein’s Method. If your appetite is whetted and you would like to read more, I would suggest starting with Sourav Chatterjee’s “A Short Survey of Stein’s Method”. This survey, contains both a short history of Stein’s method, as well as a concise summary of the extensions and generalizations that have been developed over the past 30 years (together with some nice open questions along the lines of leveraging Stein’s Method to prove limiting behaviors of various graph theoretic random variables, such as the length of the shorted traveling salesman tour on certain families of random graphs). For a more detailed reference, see the fairly recent book of Chen, Goldstein, and Shao “Normal Approximation by Stein’s Method” (which is also available for download).



Thanks for the clear post (and great exposition)! If anything, I have a possibly trivial question about one step: when bounding the sum of the two errors, how to you obtain $1+\mathbb{E}[\lvert X_1\rvert^3]$ instead of $\mathbb{E}[\lvert X\rvert]+\mathbb{E}[\lvert X_1\rvert^3]$?
LikeLike
Sorry, that was a bit of a typo—that err_2 term should have a subscript on the X, namely err_2 < (1/sqrt(n) E[|X_1|] |f''|, and by assumption, are assuming that X_i is bounded in magnitude by 1.
LikeLike
I see — thank you.
LikeLike