
Testing Juntas (or “Avoiding the Curse of Irrelevant Dimensionality”)

Juntas (or, with more words, “functions of few relevant attributes”) are a central concept in computational learning theory, analysis of Boolean functions, and machine learning. Without trying to motivate this here (see e.g. this blog post of Dick Lipton’s), let us first recap some notions.
A Boolean function 





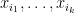



(
Now, if
So testing whether an unknown function
Given parameters
,
, and query access to an unknown Boolean function
(in Hamming distance) for any
(In the above, the main parameter is
Property testing algorithms come in many flavors: they can be non-adaptive (decide all the queries they will make to 
So what do we know thus far?
1 Surprise: there is no
Nobody likes to have three parameters, and nobody likes
Namely, they give a tester (actually, a couple) with query complexity 
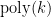
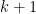
So then, it suffices to estimate the “influence” of each of these bins, and reject if more than
Note that I used the word “influence” quite a lot in the previous paragraph, and this for a good reason: the quantity at play here is the influence of a set of variables, a generalization of the standard notion of influence of a variable in Boolean analysis. Defined as
![\textrm{Inf}_f(S) \stackrel{\rm def}{=} 2\Pr_{x\sim \{-1,1\}^{[n]\setminus S}, y\sim \{-1,1\}^{S}}[ f(x\sqcup y) \neq f(x) ]](https://s0.wp.com/latex.php?latex=%5Ctextrm%7BInf%7D_f%28S%29+%5Cstackrel%7B%5Crm+def%7D%7B%3D%7D+2%5CPr_%7Bx%5Csim+%5C%7B-1%2C1%5C%7D%5E%7B%5Bn%5D%5Csetminus+S%7D%2C+y%5Csim+%5C%7B-1%2C1%5C%7D%5E%7BS%7D%7D%5B+f%28x%5Csqcup+y%29+%5Cneq+f%28x%29+%5D+&bg=ffffff&fg=000000&s=0&c=20201002)
this quantity captures the probability that “re-randomizing” the variables in 
2 Let’s bring that
After this quite amazing result, Eric Blais [Blais08, Blais09] improved this bound twice: first, establishing a non-adaptive, two-sided upper bound of 
The second algorithm yields an adaptive, one-sided upper bound of 
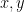


These last two upper bounds have remained unchallenged. For a rather good reason: they’re more or less tight, each of them.
Indeed, Chockler and Gutfreund [CG04], and Blais, Brody, and Matulef [BBM12] proved that 
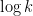

So, well, both of Blais’ testers are optimal. Are we done?
3 The Virtue of Tolerance
Not quite, actually. Up to some slack (see open problems below), we know the landscape of standard testing of
While all the above algorithms have some (very) small amount of tolerant built in (namely, something like 
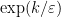
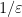
Recently, with Eric Blais, Talya Eden, Amit Levi, and Dana Ron [BCELR18], we provided two different algorithms for tolerant testing of juntas.
The first provides a smooth trade-off between the amount of tolerance guaranteed and the query complexity: for 
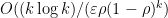
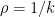


The second builds on the properties of the influence function — which is not only directly related to the distance to 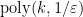

Which almost solves the question, but not quite.
4 Intolerance is Easier?
Mentioned earlier was the fact that we do not have any separation being tolerant and intolerance testers for
Any (possibly two-sided) non-adaptive tolerant tester for
(for
).
Since the standard testing version can be done with 
Now, the proof goes through a reduction to a graph testing question, in a model the authors introduce (that of rejection sampling oracle, which on query ![T\subseteq [n]](https://s0.wp.com/latex.php?latex=T%5Csubseteq+%5Bn%5D&bg=ffffff&fg=000000&s=0&c=20201002)

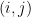


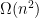
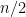

5 Open questions
The above may give the impression that all is done, and that the landscape is fully known (up to some technical details). Sadly (or fortunately), this is far from being true; below, I highlight a few question i personnally find very interesting and appealing. (I may have very bad taste, mind you)

- The role of adaptivity in standard testing. We have pretty tight bounds (up to some
- Tolerant testing. Can we get a
-query tolerant tester without the relaxation “close to
-junta$?
- Tolerant testing. Can we get a tester (even with query complexity exponential in
-far”? (It looks like that all techniques relying on using the influence function, due to its slightly-loose relation to distance to
here). If not, can we prove a lower bound against “influence-based testers”?
- Standard vs. tolerant testing. Can the separation of Levi and Waingarten be extended to adaptive algorithms?
And finally, one I am really fond of: changing the setting itself, say a function ![f\colon\mathbb{R}^n \to [-1,1]](https://s0.wp.com/latex.php?latex=f%5Ccolon%5Cmathbb%7BR%7D%5En+%5Cto+%5B-1%2C1%5D&bg=ffffff&fg=000000&s=0&c=20201002)
References.
[BBM12] Blais, Brody, and Matulef. Property testing lower bounds via communication complexity. CCC, 2012.
[BCELR18] Blais, Canonne, Eden, Levi, and Ron. Tolerant Junta Testing and the Connection to Submodular Optimization and Function Isomorphism. SODA, 2018.
[Blais08] Blais. Improved bounds for testing juntas. RANDOM, 2008.
[Blais09] Blais. Testing juntas nearly optimally. STOC, 2009.
[CG04] Chockler and Gutfreund. A lower bound for testing juntas. Information Processing Letters, 2004.
[CG17] Canonne and Gur. An adaptivity hierarchy theorem for property testing. CCC, 2017.
[CSTWX17] Chen, Servedio, Tan, Waingarten, and Xie. Settling the query complexity of non-adaptive junta testing. CCC, 2017.
[FKRSS04] Fischer, Kindler, Ron, Safra, and Samorodnitsky. Testing juntas. J. Computer
& System Sciences, 2004.
[STW15] Servedio, Tan, and Wright. Adaptivity helps for testing juntas. CCC, 2015.

Reference missing: [LW18] is https://eccc.weizmann.ac.il/report/2018/094/ (see the short summary on the Property Testing Review Blog: https://ptreview.sublinear.info/?p=999)
LikeLike