
Reading in Private

(This blog post is based on joint work with Dima Kogan.)
One of the great unsung perks of being a college student is having access to the university library. There is something thrilling about hunting down exactly the right reference deep in the stacks, or reading through the archived papers of a public figure from years back.
The pandemic has closed all of our libraries for the time being. Even so, through the fruits of computer science—databases, the Internet, e-readers, and so on—we can get access to much of the same information even when we are cooped up at home.
But for me, one of the true pleasures of using a library is the fact that I can browse through any book I want in complete privacy. If I want to go up to the stacks and read about tulip gardening, or road-bike maintenance, or strategies for managing anxiety, I can do that pretty much without anyone else knowing.
In contrast, if I go online today and search for “tulip gardening,” Google will take careful note of my interest in tulips and I will be seeing ads about gardening tools for months.
An ideal digital library would let us download and read books without anyone—not even the library itself—learning which books we are reading. How could we build such a privacy-respecting digital library?
In this post, we will discuss the private-library problem and how our recent work on private information retrieval might be able to help solve it.
The Private-Library Problem
Let us define the problem a little more precisely. We will imagine a protocol running between a library, which holds the books, and a student, who wants to download a particular book.
Say that the library has 


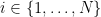
The student starts out holding the index
- Correctness. The student should have her desired book (i.e., the bit
).
- Privacy. The library should have not learned any information, in a cryptographic sense, about which book the student downloaded.
Of course, we have grossly simplified the problem: a real book is more than a single bit in length, book titles are not consecutive integers, maybe the student would like to find a book using a keyword search, etc. But even this simplified private-information-retrieval problem, which Chor, Goldreich, Kushilevitz, and Sudan introduced in the 90s, is already interesting enough.
A simple but inefficient solution
There is a simple solution to this problem: the student can just ask the library to send her the contents of all
Well, there are two problems:
- The amount of communication is large: Just to read a single book, the client must download the contents of the entire library! So this is terribly inefficient.
- The amount of computation is large: Just to fetch a single book, the library must do work proportional to the size of the entire library. So “checking out” a book from this digital library will take a long time.
Research on private information retrieval typically focuses on the first problem: how can we reduce the communication cost? Using a variety of clever techniques, it is possible to drive down the communication cost to something very small—sub-polynomial or even logarithmic in the library size
But today we are interested in the computational burden on the library. Is there any way that the student can privately download a book from the library while requiring the library to do only 
Doing the hard work in advance
To have both correctness and privacy, it seems that the library needs to touch each of the
Our idea is to have the library do the 
Later on, once the student decides which book in the library she wants to read, the student and library can run a
So, by pushing the library’s expensive linear scan to an offline phase, the library can service the student’s request for a book in sublinear online time.
Our offline/online private information retrieval scheme
Let’s see how to construct such an offline/online scheme. To make things simple for the purposes of this post, let’s assume that the student has access to two non-colluding libraries that hold the same set of books. To be concrete, let’s call the two libraries “Stanford” and “Berkeley.”
The privacy property will hold as long as the librarians at Stanford and Berkeley don’t get together and share the information that they learned while running the protocol with the student. So Stanford and Berkeley here are “non-colluding.” (Equivalently, our scheme that protects privacy against an adversary that controls one of the two libraries—but not both.)
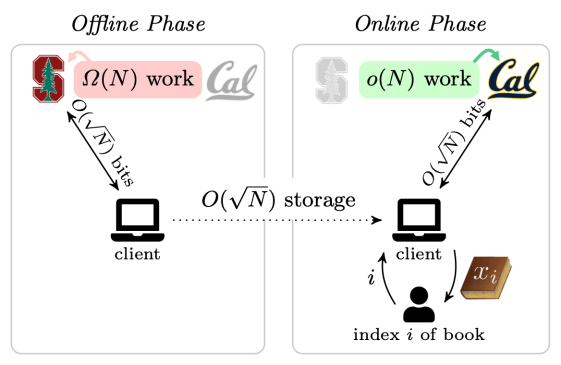
In the offline phase, which happens before the student knows which book she wants to read, the Stanford library does linear work. In the online phase, which runs once the student has the index of her desired book, the Berkeley library runs in sublinear time. (We are suppressing log factors here.)
Now, let’s describe an offline/online protocol by which the student can privately fetch a book from the digital library:
Offline Phase.
- The student partitions the integers
into
non-overlapping sets chosen at random, where each set has size
.
- The student sends these sets
- For each set
, the Stanford library computes the parity of all of the books indexed by set
to the student. In other words, if the books are
, then
.
The total communication in this phase is only 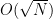
Online Phase. Once the student decides that she wants to read book
- The student finds the set
of her desired book.
- The student flips a coin that is weighted to come up heads with some probability
, to be fixed later.
- If the coin lands heads:
- The student sends
to the Berkeley library.
- The student sends
- If the coin lands tails:
- The student samples
.
- The student sends
to the Berkeley library.
- The student samples
- The Berkeley library receives the set
from the student. The Berkeley library returns the contents of all books whose indices appear in set
to the student.
- Now, the student can recover its desired book as follows:
- If heads: the student now has the parity of the books in
- If tails:
. In this case the Berkeley library has sent the contents of book
- If heads: the student now has the parity of the books in
Even before we fix the weight 
The last matter to address is privacy. Again, we are assuming that the adversary controls only one of the two libraries.
- In the offline phase, the student’s message to the Stanford library is independent of
- In the online phase, we must be more careful. It turns out that if we choose the weight
, then the set
subset of
.
Open problems
So, the student can privately fetch a book from our digital libraries in sublinear online time. What else is left to do?
- Getting rid of the need for two non-colluding libraries is a clear next step. Our work has some results along these lines, but they pay a price either in (a) asymptotic efficiency or in (b) the strength of the cryptographic assumptions required.
- A beautiful paper of Beimel, Ishai, and Malkin shows that if the library can store its collection of books using a special type of error-correcting encoding, the total computational time at the libraries (not just the online time) can be sublinear in
- Privacy is just one of the many pleasures of using a physical library. During this period of confinement, I also miss the smell of the books, the beauty of light filtering through the stacks, and the peacefulness of thinking in a study carrel. Can a digital library ever give us these things too?
If any of these questions catch your fancy, please check out our Eurocrypt paper for more background, pointers, and results.
Don Knuth has reportedly said “Using a great library to solve a specific problem… Now that […] is real living.” With better digital libraries, maybe we could all live a little bit more during these challenging days.

Leave a comment