
Incentive Compatible Sensitive Surveys

Crucial decisions are increasingly being made by automated machine learning algorithms. These algorithms rely on data, and without high quality data, the resulting decisions may be inaccurate and/or unfair. In some cases, data is readily available: for example, location data passively collected by smartphones. In other cases, data may be difficult to obtain by automated means, and it is necessary to directly survey the population.
However, individuals are not always motivated to take surveys if they receive no benefit. Offering a monetary reward may incentivize some individuals to participate, but there is a problem with this approach: what if an individual’s data is correlated with their willingness to take the survey?

For concreteness, imagine that you are a health administrator trying to estimate the average weight in a population. This is a sensitive attribute that individuals may be reluctant to disclose, especially if their weight is not considered healthy. A generic survey may yield disproportionately more respondents with “healthy” weights, and thus may result an an inaccurate estimate (see, e.g, Shields et al., 2011).

In this post, we discuss three papers which propose solutions to this problem through the lens of mechanism design. The idea is to carefully design payments so that we received an unbiased sample, leading to a hopefully accurate estimate.
Model
We use 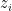

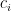

We assume that agents are drawn at random independently from some distribution. Our crucial assumption is that we known the marginal distribution of agent costs, which we denote 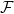
Our mechanisms consist of two parts: an allocation rule 

- Ask each agent
denote the actual reported cost.
- With probability
, we purchase the agent’s data and pay her
. With probability
, we do not buy the data, and no payment is made.
- At the end, use the data we learned to form an estimate of the population average of
denote our estimate.
In this model, agent 
We have four main requirements:
- Truthfulness. It should be in each agent’s best interest to truthfully report
- Individual rationality. Agents should not receive negative utility if they are honest, i.e., we should have
for all
- Budget constrained. Our total expected payment should not exceed
.
- Unbiased. Our estimate isn’t consistently too high or too low. Specifically, the expected value of our estimate should be equal to the true average, i.e.,
.
Lack of bias doesn’t mean that our estimate is accurate, however. To this end, our primary goal is to minimize the variance, subject to the mechanism obeying the four above criteria. We evaluate variance via a worst-case framework: given a mechanism, we wish minimize the variance with respect to the worst-case distribution of agents for that mechanism. The idea is that the distribution of

When we refer to the “optimal” mechanism, we mean minimum variance, subject to being truthful, individually rational, budget constrained, and unbiased (henceforth TIBU).
The Horvitz Thomspon Estimator
Once we have learned the

Thus our task is simply to choose
Approach #1
This model was first considered by Roth and Schoenebeck (2012). They are able to characterize a mechanism which is TIBU and has variance at most 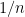

Their approach relies on Take-It-Or-Leave-It mechanisms. Such a mechanism is defined by a distribution $G$ over the positive real numbers, and works as follows:
- Each agent
- Sample a payment
from
.
- If
, buy the agent’s data with payment
, do not buy the agent’s data.

This amounts to an allocation rule ![A(c) = 1 - \text{Pr}[p\ge c]](https://s0.wp.com/latex.php?latex=A%28c%29+%3D+1+-+%5Ctext%7BPr%7D%5Bp%5Cge+c%5D&bg=ffffff&fg=000000&s=0&c=20201002)
The proof of their main result is primarily based on using the calculus of variations to optimize over the space of distributions
Approach #2
Although the above result is a great step, it leaves room for improvement. First of all, the assumption that
The approach of Chen et al. (2018) is based on two primary ideas. First, they show that any monotone allocation rule (i.e., we are always less likely to purchase data from an agent with higher cost) can be implemented in a TIBU fashion by a unique payment rule. Thus we only need to identify the optimal allocation rule. (This is similar to the standard result from auction theory about implementable monotone allocation rules (Myerson 1981).)
The second idea is to view the problem as a zero-sum game between ourselves (the mechanism designer) and an adversary who chooses the distribution of agents. Given a distribution, we choose an allocation rule to minimize the variance, and given an allocation rule, the adversary chooses a distribution to maximize the variance.

The authors are able to solve for the equilibrium of this game and thus identify the TIBU mechanism with minimum possible variance.
Approach #3
Approach #2 gave us our desired result: a minimum variance mechanism subject to our four desired properties (TIBU), for any distribution of

Chen and Zheng (2019) do away with this assumption in a follow-up paper. They consider a model where the mechanism has no prior information on the distribution of costs (or on the distribution of data), and $n$ agents arrive one-by-one in a uniformly random order. Each agent reports a cost, and we decide whether to buy her data, and what to pay her. In order to price well, we need to learn the cost distribution, but we must do this while simultaneously making irrevocable purchasing decisions. The main result is a TIBU mechanism with variance at most a constant factor worse than optimal.
The authors note that after each step 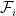
Discussion
In this post, we considered the problem of surveying a sensitive attribute where an agent’s data may be correlated with their willingness to participate. We discussed three different approaches, all of which rely of giving higher payments to agents with higher costs, in order to incentivize them to participate and to obtain an unbiased estimate. The final approach was able to give a truthful, individually rational, budget feasible, and unbiased mechanism with approximately optimal variance, without making any prior assumptions on the distribution of agents.
However, all three of the approaches assume that agents cannot lie about the data. This is reasonable for some attributes, such as a body weight, where an agent can be asked to step onto a physical scale. However, requiring participants come in person to a particular location will certainly lead to less engagement. Furthermore, for other sensitive attributes, there may not be a verifiable way to obtain the data. Future work could investigate alternative models where this assumption is not necessary. For example, perhaps agents do not maliciously lie, but rather are simply inaccurate at reporting their own attributes. For example, research has demonstrated that people consistently over-report height and under-report weight (e.g., Gorber et al., 2007). Could a mechanism learn the pattern of inaccuracy and compensate for that to still obtain an unbiased estimate?

References
- Yiling Chen, Nicole Immorlica, Brendan Lucier, Vasilis Syrgkanis, and Juba Ziani. “Optimal data acquisition for statistical estimation.” In Proceedings of the 2018 ACM Conference on Economics and Computation. 2018.
- Yiling Chen and Shuran Zheng. “Prior-free data acquisition for accurate statistical estimation.” Proceedings of the 2019 ACM Conference on Economics and Computation. 2019.
- Sarah Connor Gorber, Mark S. Tremplay, David Moher, and B. Gorber (2007). A comparison of direct vs. self‐report measures for assessing height, weight and body mass index: a systematic review. Obesity reviews, 8(4), 307-326.
- Roger Myerson. Optimal auction design. Mathematics of Operations Research, 6(1):58–73. 1981.
- Aaron Roth and Grant Schoenebeck. “Conducting truthful surveys, cheaply.” Proceedings of the 2012 ACM Conference on Electronic Commerce. 2012.
- Margot Shields, Sarah Connor Gorber, Ian Janssen, and Mark S. Tremblay. (2011). Bias in self-reported estimates of obesity in Canadian health surveys: an update on correction equations for adults. Health Reports, 22(3), 35.

Leave a comment