
Entropy Estimation via Two Chains: Streamlining the Proof of the Sunflower Lemma

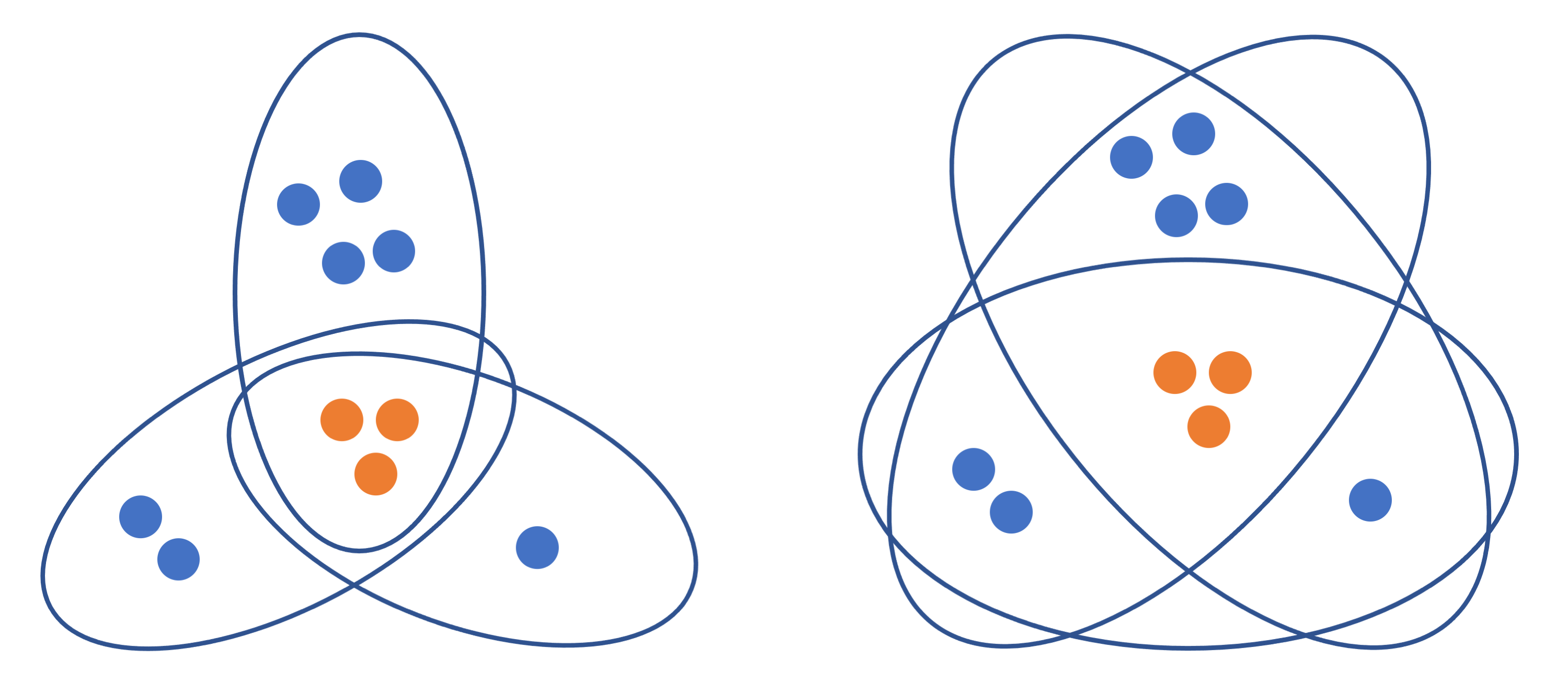
The sunflower lemma describes an interesting combinatorial property of set families: any large family of small sets must contain a large sunflower—a sub-family consisting of sets 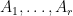


The lemma was first proved by Erdős-Rado in 1960, who gave the quantitative bound that among 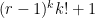









Since the breakthrough of Alweiss-Lovett-Wu-Zhang, researchers have been refining the bound and simplifying the proof. The current best bound is 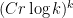
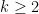
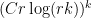
Theorem 1 (Sunflower Lemma [BCW’20]). There exists a constant 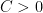
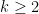
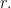
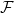
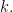
The aim of this blog post is to present a streamlined proof of Theorem 1. The proof is largely based on a blog post by Terence Tao where he presented an elegant proof of Rao’s result using Shannon entropy. However, Tao’s proof included a trick of passing to a conditional copy twice, which Tao described as “somewhat magical”. We show here that the trick is not necessary for the proof, and avoiding the trick gives a simpler proof with a slightly better constant in the bound.
We start by defining 
![[N]](https://s0.wp.com/latex.php?latex=%5BN%5D&bg=ffffff&fg=000000&s=0&c=20201002)
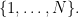
Definition 1 (Spread family). Let 

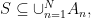
![\begin{aligned} \Pr[S\subseteq A_{\mathbf n}] \le R^{-|S|},\end{aligned}](https://s0.wp.com/latex.php?latex=%5Cbegin%7Baligned%7D+%5CPr%5BS%5Csubseteq+A_%7B%5Cmathbf+n%7D%5D+%5Cle+R%5E%7B-%7CS%7C%7D%2C%5Cend%7Baligned%7D&bg=ffffff&fg=000000&s=0&c=20201002)
where 
The main technical part of recent improvements in the sunflower lemma happens in the proof of the following refinement lemma. We use the base-
Lemma 2 (Refinement). Let 

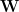
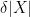
![\delta\in(1/R,1]](https://s0.wp.com/latex.php?latex=%5Cdelta%5Cin%281%2FR%2C1%5D&bg=ffffff&fg=000000&s=0&c=20201002)

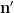

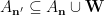
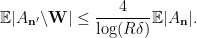
The proof of Theorem 1 using Lemma 2 can be found in Rao’s paper and Tao’s blog post, so we omit it here and focus on proving Lemma 2. Rao and Tao both proved a slightly weaker version of Theorem 1 but this weakness can be overcome using a minor twist observed by Bell-Chueluecha-Warnke. They also used slightly different forms of Lemma 2 but the differences are non-essential.
It is easy to see that in Lemma 2 one can convert 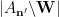
We follow Tao’s idea of proving Lemma 2 using Shannon entropy, but we present the proof in a more streamlined fashion with a slightly sharper constant in the bound (Tao proved a version of Lemma 2 where the constant 4 was replaced by 5). Specifically, we present the proof in a way resembling a basic technique in combinatorics called counting in two ways: one can show that two quantities are equal by showing that they both count the number of elements in the same set. Here, we estimate the entropy of the same collection of random variables in two different ways, and prove Lemma 2 by comparing the two estimates. The way we obtain the two estimates relies crucially on the chain rule of conditional entropy:
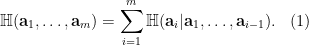
Equation (1) holds for arbitrary random variables 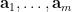
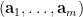
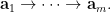
To prove Lemma 2, we obtain two entropy estimates for the same collection of random variables by applying (1) to two different chains.
We need the following useful lemmas about Shannon entropy. We omit their proofs here as they can be found in Tao’s blog post, where many basic properties of Shannon entropy are also discussed. (We also highly recommend Tao’s other blog posts about Shannon entropy and the entropy compression argument.)
Lemma 3 (Subsets of small sets have small conditional entropy). Let 
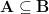

Lemma 4 (Information-theoretic interpretation of spread). Let ![[N].](https://s0.wp.com/latex.php?latex=%5BN%5D.&bg=ffffff&fg=000000&s=0&c=20201002)



Lemma 5 (Information-theoretic properties of uniformly random subsets of fixed size). Let 
![\delta\in (0,1]](https://s0.wp.com/latex.php?latex=%5Cdelta%5Cin+%280%2C1%5D&bg=ffffff&fg=000000&s=0&c=20201002)


- (absorption)
- (spread) if
almost surely, then
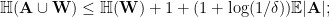
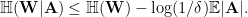
Proof of Lemma 2. If there exists ![n\in[N]](https://s0.wp.com/latex.php?latex=n%5Cin%5BN%5D&bg=ffffff&fg=000000&s=0&c=20201002)
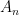

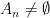
![n\in[N].](https://s0.wp.com/latex.php?latex=n%5Cin%5BN%5D.&bg=ffffff&fg=000000&s=0&c=20201002)
Following Tao’s proof, we construct 
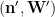
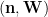
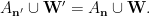
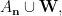
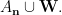

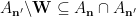
It remains to prove that the 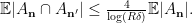
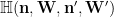
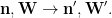
Namely, we apply (1) in the following way:
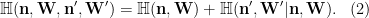
By the independence of 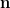

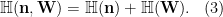
By the conditional independence of 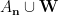
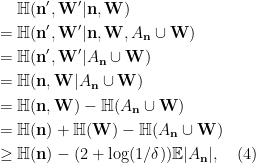
where the last inequality is by Lemma 5 Item 1. Plugging (3), (4) into (2), we get the following lower bound:
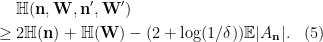
Now we establish an upper bound for
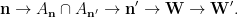
Namely, we apply (1) in the following manner:
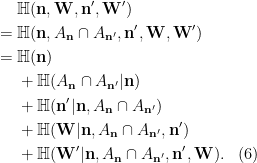
By Lemma 3 and
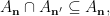

By Lemma 4 and

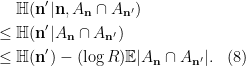
By Lemma 5 Item 2 and
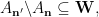
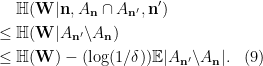
Since 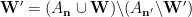
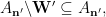
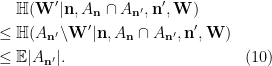
Plugging (7), (8), (9), (10) into (6) and simplifying using

we get the following upper bound:
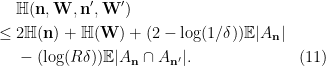
Comparing (5) and (11) proves the desired inequality
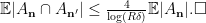
Acknowledgments. I would like to thank my quals committee, Moses Charikar, Omer Reingold, and Li-Yang Tan for valuable feedback and inspiring discussions.

Leave a comment